
Did Mars ever have environmental conditions that could have supported life? This is one of the key questions in the field of planetary science. Answering it will not only inform our expectations about whether there is life elsewhere in the universe, but it can also help us better understand how and why life developed on Earth.
NASA missions like the Curiosity and Perseverance rovers carry a rich array of instruments suited to collect data and build evidence towards answering this question. One particularly powerful capability they have is collecting rock and soil samples and taking measurements that can be used to determine their chemical makeup. These chemical signatures can indicate whether the environment's conditions could have sustained life.
While sending these complex robots and their delicate instruments over 500 million kilometers through space and landing them autonomously on Mars are awe-inspiring feats of engineering, the challenges do not stop there. Communication between rovers and Earth is severely constrained, with limited transfer rates and short daily communication windows. When scientists on Earth receive sample data from the rover, they must rapidly analyze them and make difficult inferences about the chemistry in order to prioritize the next operations and send those instructions back to the rover.
Improving methods for analyzing planetary data will help scientists more quickly and effectively conduct mission operations and maximize scientific learnings. The longer-term goal, in the future, would be to deploy sufficiently powerful methods onboard rovers to autonomously guide science operations and reduce reliance on a "ground-in-the-loop" control operations model.
In this challenge, your goal is to build a model to automatically analyze mass spectrometry data collected for Mars exploration in order to help scientists in their analysis towards understanding the present and past habitability of Mars.
Specifically, the model should detect the presence of certain families of chemical compounds in data collected from performing evolved gas analysis (EGA) on a set of analog samples. The winning techniques may be used to help analyze data from Mars, and potentially even inform future designs for planetary mission instruments performing in-situ analysis. In other words, one day your model might literally be out-of-this-world!
Some additional notes:
Understanding the data. The mass spectrometry data used in this competition can require specialist knowledge to interpret. See the Problem Description page for discussion of the data that may inform your data processing and feature engineering. If you have questions, please feel welcome to ask on the community forum.
External data use. As noted in the Challenge Rules, external data and pre-trained models are allowed in this competition as long as they are freely and publicly available with permissive open licensing. Note that many mass spectral reference libraries, including those from the National Institute of Standards and Technology (NIST), are not available with open licensing and therefore not allowed in the competition. If you are using any external datasets or pre-trained models, you are required to publicly share about them in the competition discussion forum in order to be eligible for a prize. If you have any questions, please ask on the forum.
Research nature. A focus of this challenge is to feature a new dataset for research and to engage planetary geologists, analytical chemists, and data scientists in working with it. As with any research dataset like this one, initial algorithms may pick up on correlations that are incidental to the task. Solutions in this challenge are intended to serve as a starting point for continued research and development. The challenge organizers intend to make the data available online after the competition for ongoing improvement.
BONUS PRIZE: SAM TESTBED MODELING METHODOLOGY
A subset of the test data for this competition comes from the SAM testbed, a replica of the Sample Analysis at Mars (SAM) instrument suite onboard the Curiosity rover. The top five participants ranked by performance on just the SAM testbed samples will be invited to submit a brief write-up of their methodology. A judging panel of subject matter experts will review the finalists' write-ups and select a winner based on their solution's technical merits and its potential to be applied to future data.
TIMELINE
The competition will have two phases with a timed release of additional labels that can be used for training. See the Problem Description page for more details about the dataset splits.
In this challenge, your goal is to detect the presence of certain families of chemical compounds in geological material samples using evolved gas analysis (EGA) mass spectrometry data collected for Mars exploration missions. These families are of rocks, minerals, and ionic compounds relevant to understanding the present and past conditions for life on Mars.
The data from this challenge comes from laboratory instruments at NASA's Goddard Space Flight Center and Johnson Space Center that are affiliated with the Sample Analysis at Mars (SAM) science team. SAM is an instrument suite aboard the Curiosity rover on Mars. For more about SAM and the SAM team, see the "About" page.
Features
Labels
Submissions and evaluation
Each observational unit in the dataset is a physical sample. The features for each sample are the mass spectrometry measurements from EGA and are provided as individual CSV files. There are four dimensions given in long format:
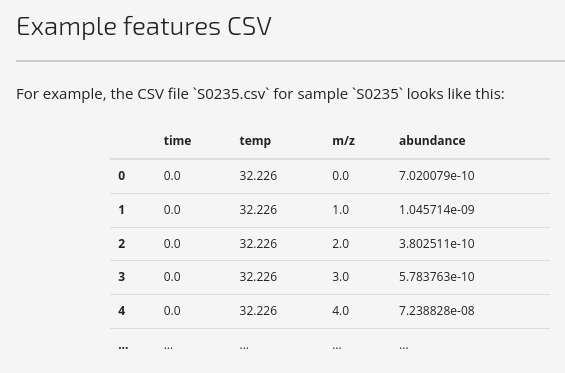
ABOUT EGA-MS
Mass spectrometry (MS) is an analytical method that can be used to determine the composition of a sample. First, the substance under analysis is ionized—the molecules are transformed into ions (electrically charged particles). During this ionization process, fragmentation occurs as energetically unstable molecular atoms dissociate. These ions pass through a stage called the mass analyzer that can separate the ions by their mass-to-charge ratio (m/z), and then the abundances (often, counts) of the separated ions are measured by an ion detector. The output measurements are typically visualized as a mass spectrum—a histogram with abundance on the y-axis and m/z on the x-axis. To infer the composition of the sample under analysis, scientists can use domain knowledge of how materials fragment under ionization or compare the mass spectrum to reference spectra measured from known substances.

Evolved gas analysis (EGA), used in generating the data for this challenge, is an analytical technique that involves heating a sample and measuring the gases released with a mass spectrometer. By introducing temperature as an additional dimension, EGA can provide more information about a sample's chemistry than mass spectrometry alone. In EGA, the sample is steadily heated up in an oven. Gases are released by desorption, dehydration, or decomposition, and these gases flow to the mass spectrometer using a carrier gas (helium in the case of the SAM instrument). The measurements by the mass spectrometer are collected as time series, and scientists can use the mass spectra to identify the gases produced from the sample over time. Based on domain knowledge of how different materials produce gases as they are heated, the composition and mineralogy of the sample can be backed out.
The figures below show the EGA data for an example sample from the training data. The mass spectrometry data is collected as a time series, and the sample's temperature over time is also collected. In the data for this competition, the temperature is already joined to the ion abundances such that each mass spectrometer measurement has an associated temperature.


UNDERSTANDING EGA–MS DATA
Some notes on how scientists typically interpret the EGA–MS data:
COMMERCIAL INSTRUMENTS VS. SAM TESTBED
The data from this competition has been collected from multiple labs from NASA's Goddard Space Flight Center and Johnson Space Center. There are differences in the feature distributions, and this can be captured by distinguishing two kinds of instruments that were used to conduct the measurements:
The instrument type for each sample in the competition data is indicated by the instrument_type column of the metadata.csv file, with values commercial and sam_testbed.
Notable differences you will see between data collected from these two types of instruments are as follows:
There are many fewer SAM testbed samples in the competition dataset than commercial samples—a consequence of the SAM testbed's uniqueness and specialized purpose. Note also that some label classes are not represented in the training data, but may be present in the test set used for final evaluation.
We expect modeling the SAM testbed samples will be a hard task! However, the ability to accurately classify samples analyzed with the SAM testbed is important to our competition sponsors. Accordingly, competitors with the top five best-performing solutions on just the SAM testbed samples in the testbed will be considered as finalists for the bonus prize. The bonus prize will be awarded for the best modeling methodology based on a submitted write-up. See "Competition Timeline and Prizes".
SUPPLEMENTAL DATA
Additional unlabeled data is provided that can be used in developing your model. These samples are provided with features only. You may find these useful for unsupervised or semi-supervised methods. We look forward to seeing what you come up with!
Note that some of the samples in the supplemental dataset were run under different experimental parameters than the primary data for the competition. This may cause the physics and chemistry in the EGA to be different and result in different distributions in the data. The differences in parameters are indicated for each sample in the supplemental_metadata.csv file. In summary, the differences are:
Samples which have carrier_gas as he and different_pressure as 0 can be expected to behave similarly to the primary data.
You are provided with multilabel binary labels for the training set. There are ten label classes, each indicating presence of material in the sample belonging to the respective rock, mineral, or ionic compound families:
Each sample can have any number of class assignments. A 1 indicates that a compound from that family is present in the sample, and a 0 indicates otherwise.
LABELS CSV
| sample_id | basalt | carbonate | chloride | iron_oxide | oxalate | oxychlorine | phyllosilicate | silicate | sulfate | sulfide |
|---|---|---|---|---|---|---|---|---|---|---|
| S0000 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| S0001 | 0 | 0 | 0 | 0 | 0 | 1 | 1 | 0 | 0 | 0 |
| S0002 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| S0003 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| S0004 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 |
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
Note that this competition's limits on rate of submissions are stricter than usual, in order to reduce the impact of overfitting and luck on the results. The dataset in this competition is relatively small, reflecting the specialized nature of the task—there is just not that much data out there for EGA for Mars planetary science. Please see the submissions page for submission restriction details and the status of your available submissions.
VALIDATION AND TEST SETS
The data for this competition is split into three sets: train, validation, and test. You will be submitting predictions for samples in the validation and test splits.
The performance metric evaluated on the validation set will be used for leaderboard ranking while the competition is open, but will not be used for final ranking and prize determination. Labels for the validation set will be released at the beginning of Phase 2: Final Training on March 8, 2022 so that you will have more data available for training your final model.
Final ranking and prizes will be based on performance on the test set. There is also a bonus prize awarded for best modeling methodology for the SAM testbed samples, with eligible finalists selected based on their performance on the SAM testbed samples within the test set.
SUBMISSION FORMAT
The format for the submission file is a CSV file. Each row should correspond to one sample and there will be one column for each label class. For each sample and each label class, there should be a numerical score in the range [0.0, 1.0] that represents the confidence of the prediction that a compound belonging to that label class family is present in the sample.
For example, if you predicted:
| sample_id | basalt | carbonate | chloride | iron_oxide | oxalate | oxychlorine | phyllosilicate | silicate | sulfate | sulfide |
|---|---|---|---|---|---|---|---|---|---|---|
| S0760 | 0.5 | 0.5 | 0.5 | 0.5 | 0.5 | 0.5 | 0.5 | 0.5 | 0.5 | 0.5 |
| S0761 | 0.5 | 0.5 | 0.5 | 0.5 | 0.5 | 0.5 | 0.5 | 0.5 | 0.5 | 0.5 |
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
| S1571 | 0.5 | 0.5 | 0.5 | 0.5 | 0.5 | 0.5 | 0.5 | 0.5 | 0.5 | 0.5 |
| S1572 | 0.5 | 0.5 | 0.5 | 0.5 | 0.5 | 0.5 | 0.5 | 0.5 | 0.5 | 0.5 |
then your .csv file that you submit would look like:
sample_id,basalt,carbonate,chloride,iron_oxide,oxalate,oxychlorine,phyllosilicate,silicate,sulfate,sulfide S0760,0.5,0.5,0.5,0.5,0.5,0.5,0.5,0.5,0.5,0.5
S0761,0.5,0.5,0.5,0.5,0.5,0.5,0.5,0.5,0.5,0.5
...
S1571,0.5,0.5,0.5,0.5,0.5,0.5,0.5,0.5,0.5,0.5
S1572,0.5,0.5,0.5,0.5,0.5,0.5,0.5,0.5,0.5,0.5
PERFORMANCE METRIC
Performance is evaluated according to aggregated log loss. Log loss (a.k.a. logistic loss or cross-entropy loss) penalizes confident but incorrect predictions. It also rewards confidence scores that are well-calibrated probabilities, meaning that they accurately reflect the long-run probability of being correct. This is an error metric, so a lower value is better.
Log loss for a single observation is calculated as follows:
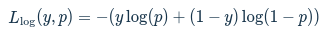
where y is a binary variable indicating whether the label is correct and pp is the user-predicted probability that the label is present. The loss for the entire dataset is the summed loss of individual observations.
The log loss scores across target label classes are aggregated with an unweighted average. This treats each observation and each label class equally, regardless of prevalence in the evaluation set.
Good luck and enjoy the challenge! We and our partners at NASA are looking forward to seeing your approaches and hopefully be able to incorporate learnings in future space missions. Check out the benchmark blog post for tips on how to get started. If you have any questions you can always visit the user forum!




