Overhead satellite imagery provides critical time-sensitive information for use areas like disaster response, navigation, and security. Most current methods for using aerial imagery assume images are taken from directly overhead, or “near-nadir”. However, the first images available are often taken from an angle, or are “oblique”. Effects from these camera orientations complicate useful tasks like change detection, vision-aided navigation, and map alignment.
In this challenge, your goal is to make satellite imagery taken from an angle more useful for time-sensitive applications like disaster and emergency response.
To take on the challenge, you will transform RGB images taken from a satellite to more accurately determine each object’s real-world structure or “geocentric pose”. Geocentric pose is an object’s height above the ground and its orientation with respect to gravity. Calculating geocentric pose helps with detecting and classifying objects and determining object boundaries.
By contributing to this challenge, you can help advance state-of-the-art methods for using and understanding satellite imagery. On your marks, get set, pose!
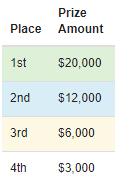
This competition will include two stages:
Prediction Contest
Submissions due July 19, 2021, 11:59 p.m. UTC
Results of predictive algorithms evaluated using the competition metric. Final rankings displayed on the private leaderboard.
Model Write-up Bonus
Submissions due Aug. 2, 2021, 11:59 p.m. UTC
Evaluated on write-ups of modeling approaches. The top 15 finalists from the Prediction Contest are eligible to submit write-ups for judging. Final winners will be selected by a judging panel.
How to compete
Click the “Compete” button in the sidebar to enroll in the competition
Create and train your own model. The benchmark blog post is a good place to start - it will be linked here once it is available.
Use your model to generate predictions that match the submission format
Click “Submit” in the sidebar, and “Make new submission”. You’re in!
Approved for public release, 21-584
Guidelines
Problem description
In this challenge, your goal is to make satellite imagery taken from a significant angle more useful for time-sensitive applications like disaster and emergency response.
This project seeks to develop an algorithm that predicts geocentric pose from single-view oblique satellite images and generalizes well to unseen world regions. Oblique images are those taken from an angle, in contrast to "nadir" images looking straight down. Geocentric pose represents object height above ground and image orientation with respect to gravity. Solutions must produce pixel-level predictions of object heights, image-level predictions of orientation angle, and image-level predictions of scale. These come together to map surface-level features to ground level.
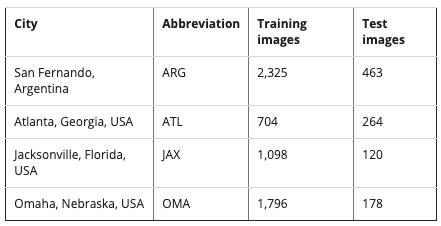
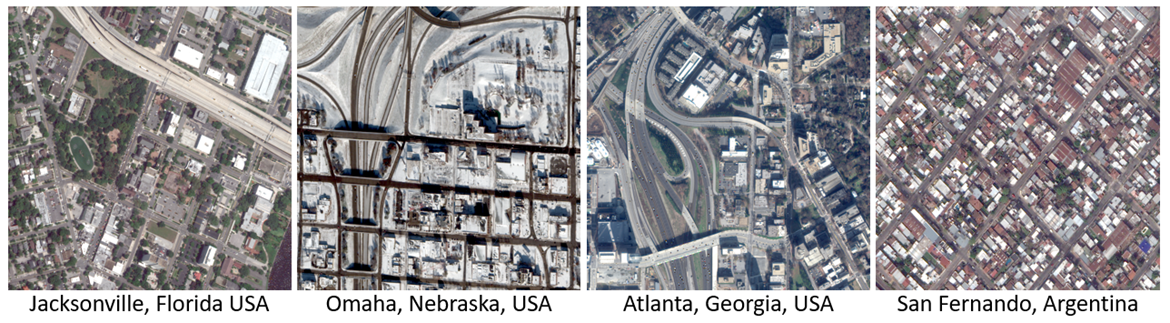
The data set for this challenge includes satellite images of four cities: Jacksonville, Florida, USA; Omaha, Nebraska, USA; Atlanta, Georgia, USA; and San Fernando, Argentina. There are a total of 5,923 training images and 1,025 test images.
Scores displayed on the public leaderboard while the competition is running may not be exactly the same as the final scores on the private leaderboard, which are used to determine final prize rankings. Variation depends on how samples from the data are used for evaluation.
Note on external data: External data is not allowed in this competition. Participants can use pre-trained computer vision models as long as they were available freely and openly in that form at the start of the competition.
Metadata for the train and test data is provided in metadata.csv. The metadata includes the following columns:
id: a randomly generated unique ID to reference each record
city: abbreviation for the geographic location
gsd: ground sample distance in meters per pixel
rgb: name of the RGB image file
An additional table is provided with geocentric pose representation for the training data. geopose_train.csv includes:
id: a randomly generated unique ID to reference each record
agl: name of the above ground level (AGL) height image file with per pixel height in cm
vflow_angle: angle (direction) of the flow vectors in the 2D image plane in radians
vflow_scale: conversion factor in centimeters per pixel between vector field magnitudes in the image and object height in the real world
RGB and AGL images for the training data are in the train folder. RGB images for the test set are in test_rgbs. The naming convention for provided image files is:
File type
Naming format
Example
RGB
[city]_[image_id]_RGB.j2k
JAX_bZxjXA_RGB.j2k
AGL
[city]_[image_id]_AGL.tif
JAX_bZxjXA_AGL.tif
FEATURES
The features in this challenge are a set of 2048 x 2048 RGB images cropped from publicly available satellite images, provided courtesy of DigitalGlobe.
Each RGB image is a JPEG 2000 file (.j2k). They have been compressed from original TIF images to preserve space. Feature data also includes the city and the ground sample distance (GSD) in meters per pixel. GSD is the average pixel size in meters.
Images in the dataset capture a variety of diverse landscapes, including different land uses, levels of urbanization, seasons, and imaging viewpoints.
Feature data example
Metadata
RGB image (JAX_bZxjXA_RGB.j2k)
array([[[152, 146, 147],
...,
[177, 179, 182]],
[[155, 149, 151],
...,
[149, 144, 140]]], dtype=uint8)
The shape of each RGB array is (2048, 2048, 3).
LABELS
An RGB satellite image taken from an angle rather than overhead (left) and the same image transformed into geocentric pose representation (right). Object height is shown in grayscale, and vectors for orientation to gravity are shown in red. Adapted from Christie et al. “Learning Geocentric Object Pose in Oblique Monocular Images.” 2020.
You’ll be asked to provide geocentric pose for each RGB image, as shown in the right image above. This includes:
1. AGL image: A 2048 x 2048 image where each pixel indicates "above ground level" (AGL) height. Test set AGLs are provided as TIF images, and height is measured in centimeters.
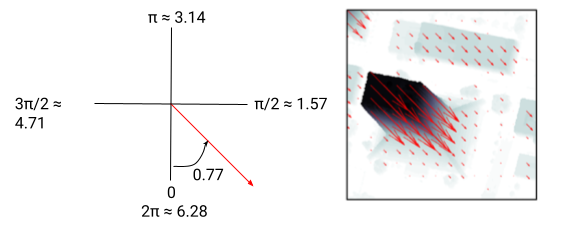
2. Angle: The angle (direction) of the flow vectors in the 2D image plane, which describes the image’s orientation with respect to gravity. Angle is measured in radians, starting from the negative y axis and increasing counterclockwise. Assume that each pixel has the same angle, so only one angle value is needed for each image. For example, the angle in the image below is 0.77 radians.
3. Scale: The conversion factor between vector field magnitudes (pixels) in the 2D plane of the image and object height (centimeters) in the real world. Scale is in pixels per centimeter and is based on the satellite’s imaging viewpoint. Scale is zero at true nadir. As with angle, assume each pixel in an image has the same scale.
True values for scale and angle are derived from satellite image metadata. True height AGLs are derived from LiDAR, a powerful remote sensing method that uses light to measure distance to the earth’s surface.
Note: Many AGL image arrays contain missing values, represented by NaN. These pixels represent locations where the LiDAR that was used to assess true height did not get any data. You can leave these values as NaN - pixels that are missing in the ground truth AGLs will be excluded from performance evaluation.
For the training dataset, vector flow scale and angle and the AGL file name are provided in geopose_train.csv.
Labelled training data example
Geocentric pose metadata
AGL image (JAX_bZxjXA_AGL.tif)
array([[8, 8, 6, ..., 0, 0, 0],
[20, 18, 4, ..., 0, 0, 0]], dtype=uint16)
The shape of the AGL array is (2048, 2048). AGLs show pixel height in cm and have data type uint16 - see the submission format section for more details.
Performance evaluation
Submissions will be evaluated using the coefficient of determination R2, which is a form of squared error normalized by the value range.
Test locations have rural, suburban, and urban scenes, each with different value ranges for object heights and their corresponding flow vectors. For leaderboard evaluation, R2 for heights and flow vectors will be assessed for each geographic location independently and then averaged to produce a final score.
Submission format
The submission file for this competition consists of geocentric pose information (AGL with pixel height, vector flow angle, and vector flow scale) for each image. See the benchmark blog post for a step-by-step walkthrough of how to save your predictions in the correct submission format. For each test set RGB image, you'll need to submit:
1. AGL image
A 2048 x 2048 .tif file with height predictions. The name of the AGL file should be <city_abbreviation>_<image_id>_AGL.tif. AGLs should show height in centimeters and have data type uint16. To make the size of participant submissions manageable, your AGL images should be saved using a lossless TIFF compression. In the benchmark, we compress each AGL TIFF by passing tiff_adobe_deflate as the compression argument to the Image.save() function from the Pillow library.
2. Vector flow
A JSON file with vector flow information. The name of the JSON file should be <city_abbreviation>_<image_id>_VFLOW.json. Example JSON file:
Scale is in pixels/cm. Angle is in radians, starting at 0 from the negative y axis and increasing counterclockwise.
Naming conventions for submission files:
File type
Naming format
Example
AGL
<city>_<image_id>_AGL.tif
JAX_bZxjXA_RGB.j2k -> JAX_bZxjXA_AGL.tif
JSON
<city>_<image_id>_VFLOW.json
JAX_bZxjXA_RGB.j2k -> JAX_bZxjXA_VFLOW.json
All of the submission files should be compressed to one .tar.gz file. Your tar.gz file for submission should be around 1.6 GB. Large tar.gz files will be rejected.
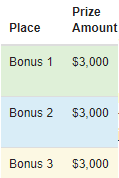
Model write-up bonus
In addition to getting the best possible predictions for rectified images, the project team is interested in identifying interesting, innovative ideas among modeling approaches. These ideas may be useful for assembling the results of the challenge for journal article submission.
Contributions of particular interest to consider for the write-up include:
Sharing insights regarding observed biases in the data and methods to enable generalization
Describing techniques for identifying failure cases and methods to address them
Identifying state of the art learning methods that can be successfully applied to our task
Documenting any other lessons learned or insights
The top 15 finalists on the private leaderboard will have the opportunity to submit a write-up of their solution using the template provided on the data download page.
EVALUATION
Bonus prizes will be awarded to the top 3 write-ups selected by a panel of judges, composed of domain experts from NGA and JHU/APL. The judging panel will evaluate each report based on the following criteria:
Rigor (40%): To what extent is the write-up built on sound, sophisticated quantitative analysis and a performant statistical model?
Innovation (40%): How useful are the contents of the write-up in expanding beyond well-established methods or using them in novel ways to tackle the challenge?
Clarity (20%): How clearly are the solution concepts, processes, and results communicated and visualized?
Note: The judging will be done primarily on a technical basis rather than on language, since many participants may not be native English speakers.
SUBMISSION FORMAT
Model write-ups will be coordinated by email for eligible finalists from the Prediction Contest.
Write-ups must be no more than 8 pages and adhere to the format requirements listed in the provided template. A sample write-up is provided for the baseline solution.
If you have any questions you can always visit the user forum. Good luck and enjoy the challenge!
Additional resources
The first published works on this task are below. The more recent CVPRW 2021 paper provides an introduction to the task as it is posed for the challenge, a description of the baseline solution, and details about the data set.
G. Christie, K. Foster, S. Hagstrom, G. D. Hager, and M. Z. Brown, “Single View Geocentric Pose in the Wild,” in CVPRW, 2021. [APL to post link when on arxiv]
The references above cite many related and motivating published works. Of particular interest for this challenge are the many related methods in monocular depth prediction. An especially intriguing recent method for monocular height prediction is reported in the following; however, note that for this challenge no semantic labels are provided.
The SpaceNet 4 public prize challenge explored the impact of oblique imaging geometry on semantic segmentation tasks. The following paper discusses one of the motivating use cases for our challenge.
If you're still assembling your submission, you have exactly 8 hours left to complete it!
Here's a Tip: HeroX recommends innovators plan to submit with at least a 3-hour window of time before the true deadline. Last-minute technical problems and unforeseen roadblocks have been the cause of many headaches. Don't let that be you!
We are quickly approaching the final days open for submission to the Overhead Geopose Challenge. The deadline is July 20, Tuesday at 7:59 pm Eastern Time (New York/USA).
Here are a couple of last-minute tips for a smooth entry process:
1. Begin your submission process several days before the cutoff time. This allows you to ensure everything you have been working on can be seamlessly integrated into the form.
2. Your submission will not be reviewed until you click the orange "Submit Entry" button at the top of the final review page. Please remember to do this!
3. Review the Challenge Guidelines to ensure your submission is complete. Pay particular attention to the judging criteria which will be the scorecard used to evaluate your entry.
4. Have any questions? Head over to the challenge forum and we would love to help you out.
There's exactly one week left to submit your solution tothe Overhead Geopose Challenge!
You're so close. You can do this!
Remember, the final submission deadline is July 20th at 7:59 pm ET. No submissions received after this time will be accepted, so make sure to get yours in as soon as possible. Any last-minute questions or concerns can go right in the comments section of this update.