The field of protein design has evolved significantly over the last four decades, transitioning from rational design to data-driven approaches. The 2024 Nobel Prize in Chemistry, awarded to Dr. Baker, for computational protein design, and to Drs. Hassabis and Jumper for protein structure prediction by AlphaFold, underscores the transformative impact of protein folding and design, highlighting the critical importance of this research in revolutionizing biological and medical sciences.
To overcome the lack of a centralized resource for designed proteins, we present the Protein Design Archive (PDA), a database and web application of structurally characterized designed proteins. Analysis of the PDA reveals growth in design complexity and biases in amino acid usage and secondary structure. The PDA aims to guide future protein design strategies by enabling data-driven insights.
The PDA is freely available at https://pragmaticproteindesign.bio.ed.ac.uk/pda/.
This project utilizes two primary data sources:
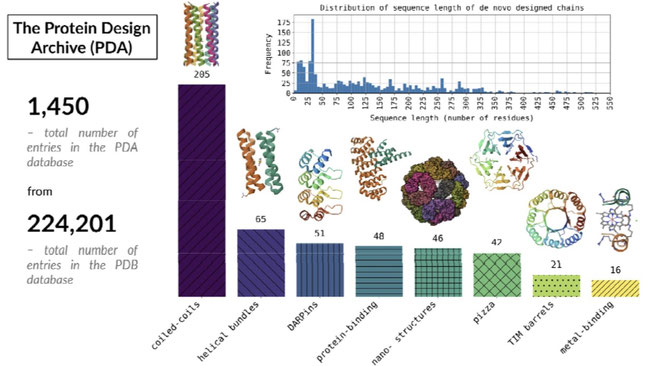
The Protein Design Archive (PDA): This database contains information on de novo designed proteins. The data includes PDB codes, release dates, classifications, amino acid sequences, structural information, and calculated properties like proteins related by sequence or structure. The source location is the PDA website (https://pragmaticproteindesign.bio.ed.ac.uk/pda/) and GitHub repository (https://github.com/wells-wood-research/chronowska-stam-wood-2024-protein-design-archive). The PDA contains 1,472 designed protein entries as of October 2024 and it continues to grow. The data types include categorical (e.g., tags labeling entries), text (e.g., PDB codes, sequences), and numerical (e.g., release date, mass, bit scores, and LDDT (Local Distance Difference Test) describing the degree of similarity between proteins.
This project analyzes designed proteins from the RCSB PDB (https://www.rcsb.org/) using bioinformatics and statistics. Data is manually curated, and analyses include comparisons of amino acid and secondary structure proportions, property calculations, and sequence/structure similarity searches.
Proposed timeline:
Data standardization and merging: Data published on the PDA will be standardized using a generalized format and merged into a single repository on Zenodo, which provides a robust and reliable platform for data sharing and archiving while adhering to FAIR (Findable, Accessible, Interoperable, Reusable) standards to facilitate easier access and analysis of the combined dataset. The dataset published on the PDA database is available for download in CSV and JSON file formats.
We will continue to develop the PDA database content with the new designed proteins structurally characterised in labs around the glove.
Following is the breakdown of the potential impact of the Protein Design Archive (PDA) project on human health and its contributions to relevant scientific disciplines:
While the PDA is primarily a research tool, it has the potential to indirectly impact human health in several ways:
By facilitating protein design research and promoting data sharing, the PDA has the potential to accelerate the development of new technologies with significant implications for human health. It's important to note that the PDA's impact on diagnosis, treatment, and prevention will be realized indirectly through the research it enables and the innovations it inspires.
This project is a collaboration between UK and USA/Italian researchers with expertise in protein design, structural biology, and bioinformatics. The team includes:
The success of the Protein Design Archive (PDA) project relies on key factors:
