Coordinating our nation’s airways is the role of the National Airspace System (NAS): “a network of both controlled and uncontrolled airspace, both domestic and oceanic.” The NAS is arguably the most complex transportation system in the world. Operational changes can save or cost airlines, taxpayers, consumers, and the economy at large thousands to millions of dollars on a regular basis. It is critical that decisions to change procedures are done with as much lead time and certainty as possible. The NAS is investing in new ways to bring vast amounts of data together with state-of-the-art machine learning to improve air travel for everyone.
An important part of this equation is airport configuration, the combination of runways used for arrivals and departures and the flow direction on those runways. For example, one configuration may use a set of runways in a north-to-south flow (or just "south flow") while another uses south-to-north flow ("north flow"). Air traffic officials may perform an airport configuration change depending on weather, traffic, or other inputs.
These changes can result in delays to flights, which may have to alter their flight paths well ahead of reaching the airport to get into the correct alignment or enter holding patterns in the air as the flows are altered. The decisions to change the airport configuration are driven by data and observations, meaning it is possible to predict these changes in advance and give flight operators time to adjust schedules, avoiding delays and wasted fuel.
Task
The goal of this challenge is to automatically predict airport configuration changes from data sources including air traffic and weather. Better algorithms for predicting future airport configurations can support critical decisions, reduce costs and fuel use, and mitigate delays across the national airspace network.
Prize eligibility
All eligible participants are invited to register to participate in the Open Arena.
For this challenge, cash prizes are restricted to Official Representatives (individual participants or team leads, in the case of a group project) who, at the time of entry, are age 18 or older, a U.S. citizen or permanent resident of the United States or its territories, and are affiliated with an accredited U.S. university either as an enrolled student or faculty member. Proof of enrollment or employment is required to demonstrate university affiliation.
For complete rules on eligibility and prizes see the Competition Rules.
Contest arenas
This challenge features two competition arenas which provide different access levels and capabilities.
The Open arena is the first step in the competition process. Here all participants can enter the outputs of their solutions-in-development to see how they fare against others on the open leaderboard.
After submitting proof of eligibility, you will be able to access the Prescreened arena. Here participants can continue to tweak their solutions, submit their executable code, and see how they perform on the prescreened leaderboard. A submission to the Prescreened arena is required to be eligible for prizes.
Open arena
Available to all registered participants
Access the public ground truth data
Submit CSV files with predictions for the leaderboard set
View the open leaderboard with live results from the best-scoring submissions
Prescreened arena
Available to approved university-affiliated participants
Access the public ground truth data
Submit trained models and code to run in the cloud
View the prescreened leaderboard with live results from the best-scoring submissions
Submit Final Scoring code submissions
Only participants in the Prescreened Arena will be eligible to win Final Scoring prizes. For more information on staging, submissions, check out the challenge guidelines.
Prizes
Total: $40,000
1st
$20,000
2nd
$10,000
3rd
$6,000
4th
$4,000
Guidelines
In this challenge, you will predict how an airport will be configured in the future. The primary data will consist of historical air traffic data and weather predictions. You may also request additional free, public datasets. Your goal is to build a model that predicts the probability of each airport configuration every 30 minutes up to 6 hours into the future. The solution should generalize to multiple airports, each with its own unique set of runways and airport configurations. How you accomplish that is up to you; you might train one model per airport, or find a way to combine information across all airports.
Features
This challenge is possible because of the enormous effort that NASA, the FAA, airlines, and other agencies undertake to collect, process, and distribute to decision makers in near real-time. You will be working with around a year of historical data, but any solution you develop using this data could be translated directly into a pipeline with access to these same features in real-time. None of the data contains sensitive data elements or sensitive flight data.
All data sources detailed below are pre-approved for both model training and testing. If you are interested in using additional data sources, see the process for requesting additional data sources.
Air traffic: Fuser, a data processing platform designed by NASA as part of the ATD-2 project, will be the primary source of air traffic data. Fuser processes the FAA’s raw data stream and distributes cleaned, real-time data on the status of individual flights nationwide. An extract of Fuser data will be available containing the following tables:
MFS: a subset of the NASA Fuser flight level data
TFM (traffic flow management) estimated time of arrival (ETA)
TFMS (traffic flow management system) estimated time of departure (ETD)
First position: the first time the aircraft was tracked to provide improved ETA estimate for arrivals
Airport configuration and layout:
Actual airport configuration via D-ATIS
Actual runways used and the associated time
Airport layout: A GeoJSON file that includes not only the layout of runways (which could be important information in conjunction with wind direction, for example) but other airport infrastructure such as buildings and roadways.
Weather: LAMP (Localized Aviation MOS (Model Output Statistics) Program), a weather forecast service operated by the National Weather Service, will be the primary source of weather data. It includes data for each of the airport facilities in the challenge. In addition to the temperature and humidity you’ll find in your favorite weather app, LAMP includes quantities that are particularly relevant to aviation, such as visibility, cloud ceiling, and likelihood of lightning. LAMP includes not only the retrospective weather, but also historical weather predictions, that is, at a point in time in the past, what we thought the weather was going to be. In other words, consider the weather at noon yesterday. In hindsight I know it was sunny (retrospective), but what was my prediction at 9 AM yesterday (historical prediction)? This distinction is critical to making sure our models do not rely on information from the future, but also giving your models access to the best weather predictions at the time they were available. An extract of LAMP predictions will be available with the following format:
Additional datasets
The official competition dataset includes important predictors of airport configuration, but there could be other datasets or other domains entirely that provide important context for the challenge. Additional data sources may be explored and incorporated during model training. However, only pre-approved data sources are allowed for generating predictions during evaluation. If you would like for any additional sources to be approved for use during inference, you are welcome to submit an official request through the competition forum.
Datasets should meet the following requirements to be considered:
Free and publicly available.
Stable and real-time enough that we can count on being able to have an extract relevant to the final evaluation time range. We want to make sure that participants don’t waste time learning to use features that are not available for the final evaluation dataset!
Compatible with real-time applications. You should be able to make a clear case that the data could conceivably be used in a future real-time application.
Approved data sources will be added to the competition data and will be made available for all participants.
The deadline for submitting a request is March 15th, and we will approve the final list of datasets by March 25th.
Sherlock OpenData Warehouse
One potential source for flight-related data is the Sherlock OpenData Warehouse, which provides access to a variety of NAS data in aggregated forms. This includes airport and runway usage over time, flight traffic aggregated by sector and center, TRACON reports, and more. While some of this data is similar to what will be available from Fuser, it is processed in a different way, and uses some different sources. Note that data in Sherlock has undergone less scrutiny than the Fuser data and may have some gaps or quality issues. When using this data, it may be important to validate beforehand that the desired data is available.
But Sherlock isn’t the only option; part of the potential for innovation comes from discovering those datasets and how best to incorporate them. We encourage you to be creative!
Requesting an additional dataset
If you find a dataset that you would like to use in the competition, create a post in the competition forum with the topic “External Data Request: [[Name of dataset. Example: Better weather forecasts]]”. Fill in this template for the post:
Short description of the dataset: [[Example: This dataset provides better weather forecasts from around the country.]]
Link to dataset: [[Example: https://betterweatherforecasts.org]]
Link to associated code, if available: [[Example: https://www.github.com/myuser/better-weather-scripts. Any code that is helpful for processing the dataset, preferably code that can produce a dataset extract for the same time range as the official competition data.]]
Leaderboard dataset
The Leaderboard dataset consists of roughly 20% of the weeks from the same time range as the training data and includes the same 10 airports as the training data. We will score submissions to both the Open and Prescreened arenas according to the metric and post the results to the respective leaderboard. Note that leaderboard ranking at the close of the competition does not determine the prize winners; it is only intended to give you a sense for how your solution compares to others.
Final evaluation dataset
The Final evaluation dataset consists of data collected for a period of approximately one month after submissions close from the same 10 airports as the training and leaderboard datasets. Participants in the Prescreened arena can submit their trained model and inference code to the code execution platform. When the challenge ends, we will take your most recent submission and re-run your code to generate predictions for the final evaluation dataset. We will score your model’s predictions using the same metric used for the Open and Prescreened leaderboards. Participants who achieve the best scores on this final evaluation will receive prizes (subject to code review).
Keep in mind that there is likely to be strong seasonality to the data and that the test set will come exclusively from the historically stormy season.
Labels
Your model should predict future airport configurations. To understand the label format, it will help to learn a bit about how runways are named: we tend to think of a runway as a physical strip of asphalt, but in practice runways are identified by codes that communicate the physical strip plus the direction that traffic flows on that strip (an important distinction, as you might imagine). The direction is expressed as the flow direction compass heading divided by 10, rounded to the nearest integer, and padded to two digits, so between 01 and 36. Each physical runway then is assigned two runway codes for flow directions rotated 180° from each other, for example 18 and 36. In airports where two runways share the same heading, L (left) and R (right) suffixes are used to disambiguate the runways, e.g., 18L/36L, 18R/36R. If there is a third, the C (center) suffix is used. In airports where four or more runways share the same heading, one runway is assigned a code using the actual heading, and subsequent runways are assigned a code using the actual heading decremented by one (two, three, and so on) so that all runways have unique codes.
With these runway codes defined, the entire airport configuration can be expressed as a string that combines the active departure and arrival runways. The string starts with “D_” for departure followed by the codes for all runways active for departures separated by an underscore, followed by “_A_” for arrival followed by the codes for all runways active for arrival separated by an underscore. For example, the airport configuration code “D_01L_18L_A_01R_18R” indicates that runways 01L and 18L are being used for departing flights and runways 01R and 18R are being used for arriving flights.
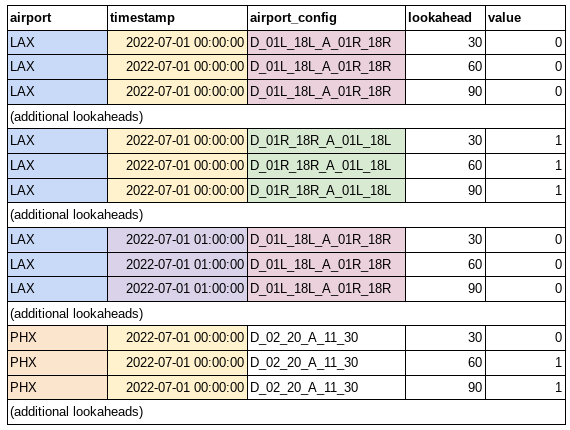
The target for your prediction is the actual airport configuration for each airport every 30 minutes up to 6 hours into the future. Predictions are made every hour. Only one configuration is active at a time. Labels for the training dataset are provided as a tidy CSV with the following format:
Where a value of 1 indicates that the configuration was active at the airport lookahead minutes after the timestamp. Note that this format contains redundant information; the active configuration for 9:00 at 2 hour lookahead (11:00) is the same as the configuration for 10:00 at 1 hour lookahead (also 11:00).
Performance metric
To measure your model's accuracy by looking at prediction error, we'll use a metric called log loss. This is an error metric, so a lower value is better (as opposed to an accuracy metric, where a higher value is better). Log loss can be calculated as follows:
loss=−1N⋅∑i=1N∑j=1Myijlogpij
where N is the number of observations, M is the number of classes (in terms of our problem M is the number of airport configurations), yij is a binary variable indicating if classification for observation i was correct, and pij was the user-predicted probability that label j applies to observation i.
The metric assumes that the probabilities for airport configurations at a single timestamp, airport, and lookahead time sum to 1, although the scorer will not enforce this constraint. You are encouraged to enforce it when preparing your submissions.
Submission format
Leaderboard dataset
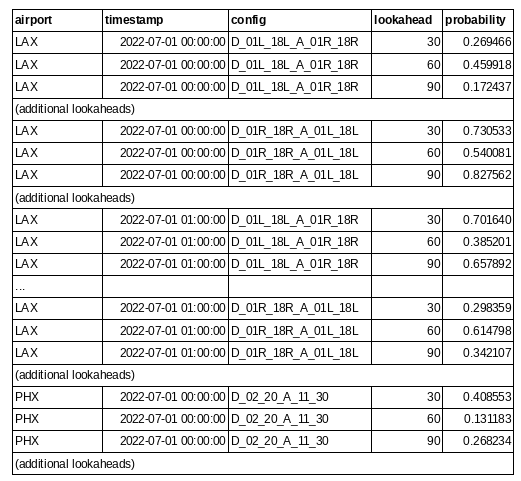
For the Open arena, you will be submitting a tidy CSV of predictions for each airport, timestamp, airport configuration, and lookahead in the leaderboard dataset. The CSV format is identical to the label format, except with predicted probability replacing the ground truth column:
Final evaluation dataset
Since the Final evaluation dataset will be collected after the close of the competition, you will submit your trained model assets and the code required to generate the predictions in the Prescreened arena. Your code should write its predictions to a CSV file named submission.csv with the same format used in the Open arena submissions.
We will run your code using the competition runtime, a Docker image defined in the competition runtime repository. Follow the instructions in the README to confirm that your submission runs without error in the competition runtime. Only submissions that run successfully will be eligible for prizes.
If you’re wondering how to get started, check out our benchmark blog post.
Good luck and enjoy this challenge! If you have any questions you can always visit the user forum.
About the Project
Project background
The nature of air travel is connecting far-flung places; the downside is that events in one location can have ripple effects throughout the system. Effective decision-making needs to consider a large number of factors, and the right decision might not always be the intuitive one. Furthermore, the drivers for these decisions are highly uncertain systems in their own right; weather is the major driver of delays in the NAS, for example. Airlines and the Federal Aviation Administration have many decision-support tools at their disposal to make the most informed decisions as possible. The stakeholders for these tools are always seeking better algorithms, predictors, optimization approaches, and other elements to gain some predictability and save on costs.
Prior work in airport configuration prediction has relied upon custom solutions for individual airports, based on case studies, rigorous analysis of historic data, and interviews with airport operators and air traffic controllers to define the process used to make configuration decisions. This method requires a large amount of manual effort for each airport at which the system should work. Two factors are converging to make this process easier and more accurate in the future. The first is simply the ongoing advancement in machine learning tools and processes. The second is the development of bigger and better real-time streams for flight, weather, and other types of data that can feed the machine learning methods.
The FAA works with airports, airlines, and other flight operators to collect raw data about all flights in the NAS and distribute that data via SWIM (System-Wide Information Management). As part of the Airspace Technology Demonstrations 2 (ATD-2) project, NASA developed Fuser to process this torrent of raw data and provide cleaned, real-time data on the status of individual flights nationwide, facilitating downstream air traffic management tools. The ATD-2 project has already used Fuser to implement various data-driven machine learning systems to predict airport configuration, runway assignment, taxi time, and more.
About the NASA team
In recent years, the amount of data available in the NAS has exploded, as has the capability of data science algorithms to extract meaning and make decisions from large volumes of data. For example, NASA’s Airspace Technology Demonstrations project has made use of machine learning as part of the Integrated Arrival/Departure/Surface (IADS) system to optimize traffic at airports. Efforts such as this have shown that the main bottleneck now is the effort of accessing, understanding, and consuming many disparate data feeds from many different sources. The goal of the Digital Information Platform is to provide a consistent, easy to use platform where a wide variety of NAS data is readily available. This will accelerate the transformation of the NAS by facilitating the development of state-of-the-art data-driven services for use by both traditional airlines and emergent operations like Unmanned Aerial Systems and Urban Air Mobility.
This challenge will function as an early use case to demonstrate the potential that such services can reach with access to high-quality data. Not only will the winning algorithms inform future work on airport configuration prediction, but every team’s experience during the challenge will inform the design and development of the Platform as a whole.
Additional resources
Introduction to Air Traffic Management, NASA Berkeley Aviation Data Science Seminars
In a typical competition, you would train your model and generate predictions for the evaluation dataset on your local machine. Then you would submit predictions to the DrivenData competition for scoring. For this competition, you will submit your trained model itself and the code to run it, and we will generate outputs for the evaluation dataset in a containerized runtime in our cloud environment.
What to submit
Your final submission should be a zip archive named with the extension .zip (for example, submission.zip). The root level of the submission.zip file must contain a main.py that processes a test dataset and writes the output to a file named submission.csv in the same directory as the main script.
For more detail on how to create and test your submission, visit the runtime repository. The repository also contains an example submission to help you get started.
Runtime
Your code is executed within a container that is defined in our runtime repository. The limits are as follows:
Your submission must be written for Python (3.9.7) and must use the packages defined in the runtime repository.
The submission must complete execution in 2 hours or less. This limit is especially helpful to address non-terminating code, and we expect most submissions to complete more quickly. If you find yourself requiring more time than this limit allows, open a Github issue in the repository to let us know.
The container runtime has access to a single GPU. All of your code should run within the GPU environments in the container, even if actual computation happens on the CPU. (CPU environments are provided within the container for local debugging only.)
The container has access to 6 vCPUs powered by an Intel Xeon E5-2690 chip and 56GB RAM.
The container has 1 Tesla K80 GPU with 12GB of memory.
The container will not have network access. All necessary files (code and model assets) must be included in your submission.
The container execution will not have root access to the filesystem.
The machines for executing your code are a shared resource across competitors. Please be conscientious in your use of them. Please add progress information to your logs and cancel jobs that will run longer than the time limit. Canceled jobs won't count against your submission limit, and this means more available resources to score submissions that will complete on time.
Requesting package installations
Since the Docker container will not have network access, all packages must be pre-installed. We are happy to add packages as long as they do not conflict and can build successfully. Packages must be available through conda for Python 3.8.5. To request additional packages be added to the docker image, follow the instructions in the runtime repository.
Happy building! Once again, if you have any questions or issues you can always head on over the user forum!
And so it begins! Welcome to the Run-way Function Challenge for NASA. We are excited to hear all of the wonderful ideas from innovators across the world.
This challenge is for individuals and teams affiliated with U.S. Universities - students or faculty.
If you’re ever feeling stuck, the challenge forum is the first place to go. The forum is there for you to ask questions and seek advice. Bounce ideas around, get to know your fellow innovators, and maybe even form a team.
Now get cracking! We can’t wait to see what you come up with.
This challenge is being implemented by HeroX's valued partner DrivenData.org. To participate in this challenge, you will be navigated to their crowdsourcing platform. To begin, click the "Learn More" button.