Summary
Updates1
Forum
Teams3
Data Track A: Financial Crime Track
Data Track B: Pandemic Forecasting Track
Summary
Overview
Privacy-enhancing technologies (PETs) have the potential to unlock more trustworthy innovation in data analysis and machine learning. Federated learning is one such technology that enables organizations to analyze sensitive data while providing improved privacy protections. These technologies could advance innovation and collaboration in new fields and help harness the power of data to tackle some of our most pressing societal challenges.
That’s why the U.S. and U.K. governments are partnering to deliver a set of prize challenges to unleash the potential of these democracy-affirming technologies to make a positive impact. In particular, this challenge will tackle two critical problems via separate data tracks: Data Track A will help with the identification of financial crime, while Data Track B will bolster pandemic responses.
By entering the prize challenges, innovators will have the opportunity to compete for cash prizes and engage with regulators and government agencies. Announced at the Summit for Democracy in December 2021, the prize challenges are a product of a collaboration between multiple government departments and agencies on both sides of the Atlantic. Winning solutions will have the opportunity to be profiled at the second Summit for Democracy, to be convened by President Joe Biden, in early 2023.
This prize challenge and its U.K. counterpart have been developed as part of a joint collaboration between the United Kingdom and the United States.
Guidelines
Objectives
The goal of this prize challenge is to mature federated learning approaches and build trust in their adoption. The challenge organizers hope to accelerate the development of efficient privacy-preserving federated learning solutions that leverage a combination of input and output privacy techniques to:
Drive innovation in the technological development and application of novel privacy enhancing technologies
Deliver strong privacy guarantees against a set of common threats and privacy attacks
Generate effective models to accomplish a set of predictive or analytical tasks that support the use cases
Challenge Structure
You will develop solutions that enhance privacy protections across the lifecycle of federated learning. This challenge offers two different data use cases—financial crime prevention (Track A) and pandemic response and forecasting (Track B). You may develop solutions directed to either one or both tracks. If you choose to develop and submit a generalizable solution to run on both Track A and B, you can also qualify for additional prizes dedicated to Generalizable Solutions.
Data Track A – Financial crime prevention – The United Nations estimates that up to $2 trillion of cross-border money laundering takes place each year, financing organized crime and undermining economic prosperity. Financial institutions such as banks and credit agencies, along with organizations that process transactions between institutions, such as the SWIFT global financial messaging provider, must protect personal and financial data, while also trying to report and deter illicit financial activities. Using synthetic datasets provided by SWIFT, you will design and later develop innovative privacy preserving federated learning solutions that facilitate cross-institution and cross-border anomaly detection and combat financial crime. Check out the Financial Crime overview page for more information.
Data Track B – Pandemic response and forecasting – As we continue to deal with COVID-19, it has become apparent that better ways to harness the power of data through analytics are critical for preparing for and responding to public health crises. Federated learning approaches could allow for responsible use of sensitive data to develop cross-organization and cross-border data analysis that would result in more robust forecasting and pandemic response capabilities. Using synthetic population datasets, you will design and later develop privacy preserving federated learning solutions that can predict an individual’s risk for infection. Check out the Pandemic Forecasting overview page for more information.
Generalizable Solutions – Cross-organization, cross-border use cases are certainly not limited to the financial or public health domains. Developing out-of-the-box generalized models that can be adjusted for use with specific data or problem sets has great potential to advance the adoption and widespread use of privacy-preserving federated learning for public- and private-sector organizations in multiple sectors. To demonstrate generalizability, you may develop a solution using both the Track A and Track B datasets to be eligible for additional awards dedicated to generalizable solutions.
More information on how to get started can be found in the Problem Description.
ELIGIBILITY
At the time of entry, the Official Representative (individual or team lead, in the case of a group project) must be age 18 or older and a U.S. citizen or permanent resident of the United States or its territories. In the case of a private entity, the business shall be incorporated in and maintain a place of business in the United States or its territories.
You may only compete in one of the two global (U.S. or U.K.) Privacy Enhancing Technologies Challenges. You must choose to register via either the U.S. or U.K. Competition Website. If you wish to instead participate in the U.K. competition, please register here.
This is the first in a series of challenge phases with a total prize pool of $800,000! Each phase in the PETs Prize Challenge invites participants to further test and apply their innovations in privacy-preserving federated learning. The overall challenge takes a red team/blue team approach: Blue Teams develop privacy-preserving solutions, while Red Teams act as adversaries to test the those solutions. Phase 1 is for Blue Teams to begin development on their solutions.
Note that your team must register and meet all requirements for Phase 1 in order to continue on to be eligible to participate Phase 2.
PHASE 1 KEY DATES
Registration & Launch: July 20, 2022
Abstract Due & Registration Closes: September 4, 2022 (11:59:59 PM UTC)
Concept Paper Due: September 19, 2022 (11:59:59 PM UTC)
Judging and Evaluation: September 19–October 24, 2022, 2022
Winners Announced: October 24, 2022
PHASE 1 PRIZES
Concept Paper Deadline:
Sept. 19, 2022, 11:59 p.m. UTC
Place
Prize Amount
1st
$30,000
2nd
$15,000
3rd
$10,000
Full Challenge Timeline and Prizes
TIMELINE OVERVIEW
There are three main phases in the challenge with two types of participants based on a red team/blue team approach. Blue Teams develop privacy-preserving solutions, while Red Teams act as adversaries to test the those solutions.
Phase 1: Concept Development (Jul–Sept 2022): Blue Teams propose privacy-preserving federated learning solution concepts.
Phase 2: Solution Development (Oct 2022–Jan 2023): Blue Teams develop working prototypes of their solutions.
Phase 3: Red Teaming (Nov 2022–Feb 2023: Red Teams prepare and test privacy attacks on top blue team solutions from Phase 2.
PRIZE OVERVIEW
Track
Prize Pool
Phase 1: Concept Paper (CURRENT)
$55,000
Phase 2: Solution Development
$575,000
Phase 3: Red Teaming
$120,000
Open Source
$50,000
Total
$800,000
PHASE DETAILS AND PRIZES
Place
Prize Amount
1st
$30,000
2nd
$15,000
3rd
$10,000
Phase 1: Concept Paper
JULY 20–SEPTEMBER 19, 2022 (YOU ARE HERE)
Participants will produce an abstract and technical concept paper laying out their proposed solution. Concept papers will be evaluated by a panel of judges across a set of weighted criteria. Participants will be eligible to win prizes awarded to the top technical papers, ranked by points awarded. Participants must complete a paper in Phase 1 in order to be eligible to compete in Phase 2.
Open to Blue Team participants.
DATA TRACK A: FINANCIAL CRIME PREVENTION
Prize Amount
1st
$100,000
2nd
$50,000
3rd
$25,000
DATA TRACK B: PANDEMIC RESPONSE AND FORECASTING
Prize Amount
1st
$100,000
2nd
$50,000
3rd
$25,000
GENERALIZED SOLUTIONS
Prize Amount
1st
$100,000
2nd
$50,000
3rd
$25,000
SPECIAL RECOGNITION
Prize Amount
Pool
$50,000
Phase 2: Solution Development
OCTOBER 5, 2022–JANUARY 25, 2023
Put your papers into action! Registered teams from Phase 1 will develop working prototypes and submit them to a remote execution environment for federated training and evaluation. These solutions are expected to be functional, i.e., capable of training a model and predicting against the evaluation data set with measurement of relevant performance and accuracy metrics. Solutions will be evaluated by a panel of judges across a set of weighted criteria. The top solutions, ranked by points awarded, will have their final rankings determined by incorporating red team evaluation from the red teams from Phase 3.
Teams can qualify for one or multiple of Data Track A: Financial Crime Prevention, Data Track B: Pandemic Response and Forecasting, and Generalized Solutions prize categories depending on how their solutions address the two machine learning tasks in the challenge.
A separate Special Recognition prize pool is set aside to award up to five solutions that do not win prizes from the three main prize categories but demonstrate excellence in specific areas of privacy innovation: novelty, advancement in a specific privacy technology, usability, efficiency.
Open to Blue Team participants.
Prize Amount
1st
$60,000
2nd
$40,000
3rd
$20,000
Phase 3: Red Teaming
NOVEMBER 1, 2022–FEBRUARY 28, 2023
Privacy researchers are invited to form red teams to put the privacy claims of Phase 2's blue team finalists to the test. The red teams will prepare and test privacy attacks on the Phase 2 finalist solutions, which be incorporated into the final Phase 2 rankings. Top red teams will be evaluated for success and rigor and be awarded prizes for this phase.
Open to Red Team participants.
Prize Amount
Pool
$50,000
Open Source
SUBMISSIONS DUE APRIL 7, 2023
Up to 5 of the final winners from Phase 2 are eligible for Open Source Award prizes upon release to an open-source repository and will evenly split the prize pool.
Open to Blue Team winners from Phase 2.
How to compete (Phase 1)
Click the "Compete!" button in the sidebar to enroll in the competition.
Click on "Team" if you need to create or join a team with other participants.
Get familiar with the problem through the data overview and problem description pages.
Summarize your modeling and privacy preserving techniques in an abstract, making sure to follow the instructions on the problem description page. Submit it by clicking on "Abstract Submission" in the sidebar. Partway there!
Describe your modeling and privacy preserving techniques in a concept paper, making sure to follow the instructions on the problem description page. Submit it by clicking on "Concept Paper Submission" in the sidebar. You're in!
Note that registration closes on September 4, 2022 at the same time that abstracts are due. Your team must register by this deadline to participate in Phase 1 or Phase 2 of the challenge.
Problem description
The objective of the challenge is to develop a privacy-preserving federated learning solution that is capable of training an effective model while providing a demonstrable level of privacy against a broad range of privacy threats. For the purposes of this challenge, a privacy-preserving solution is defined as one which is able to provably ensure that sensitive information in the datasets remain confidential to the respective data owners across the machine learning lifecycle. This requires the raw data is protected during training (input privacy), and that it also cannot be reverse-engineered during inference (output privacy).
In Phase 1, your goal is to write a concept paper describing a privacy-preserving federated learning solution that tackles one or both of two tasks: financial crime prevention or pandemic forecasting. The challenge organizers are interested in efficient and usable federated learning solutions that provide end-to-end privacy and security protections while harnessing the potential of AI for overcoming significant global challenges.
Solutions should aim to:
Provide robust privacy protection for the collaborating parties
Minimize loss of overall accuracy in the model
Minimize additional computational resources (including compute, memory, communication), as compared to a non-federated learning approach.
In addition to this, the evaluation process will reward competitors who:
Show a high degree of novelty or innovation
Demonstrate how their solution (or parts of it) could be applied or generalized to other use cases
Effectively prove or demonstrate the privacy guarantees offered by their solution, in a form that is comprehensible to data owners or regulators
Consider how their solution could be applied in a production environment
More information on the concept paper evaluation criteria and submission specifications is provided below. You can read more about the data for the separate tracks on the financial crime and pandemic forecasting data overview pages.
In Phase 1, there are two deadlines—one for registration and the abstract, and one for the concept paper. Teams must both register and submit an abstract by the abstract deadline in order to submit a concept paper and in order to compete in Phase 2.
Key Dates
Launch & Blue Team Registration Opened
July 20, 2022
Abstracts Due & Blue Team Registration Closed
September 4, 2022 at 11:59:59 PM UTC
Concept Papers Due
September 19, 2022 at 11:59:59 PM UTC
Winners Announced
October 24, 2022
Phase 2 Tracks and Prizes
In order to participate in the upcoming Phase 2, your team must submit a concept paper in Phase 1 (this phase) for the solution(s) you intend to develop.
In Phase 2, prizes are awarded in separate categories for top solutions for each of the two Data Tracks as well as for Generalized Solutions. Teams can win prizes across multiple of the three categories but are required in Phase 1 in their concept papers to declare how their solutions apply to which prize categories. You can read more about the data tracks on the respective pages for Track A: Financial Crime and Track B: Pandemic Forecasting.
You can choose to develop a solution for either Track A or Track B, or develop two solutions total—one for each track.
A solution in Phase 2 is eligible to be considered for a prize for the respective track's top solutions prize category.
In order to have two solutions—you must submit two concept papers in Phase 1. Teams may win at most one prize in Phase 1, no matter whether they submit one or two concept papers. However, teams with two solutions may win up to two top solution prizes in Phase 2—each of their solutions will be considered for a prize for their respective data tracks.
Alternatively, you can choose to develop a single generalized solution.
A generalized solution is one where the same core privacy techniques and proofs apply to both use cases, and adaptations to specific use cases are relatively minor and separable from the shared core. (The specific privacy claims or guarantees as a result of those proofs may differ by use case.)
Generalized solutions may win up to three prizes—one from each of the two data track prize categories, and a third from a prize category for top generalized solutions.
Phase 2 has a total expected prize pool of $575,000. You can see anticipated prize structure in Phase 2 with individual prize amounts on the home page.
About Federated Learning
Federated learning (FL), also known as collaborative learning, is a technique for collaboratively training a shared machine learning model across data from multiple parties while preserving each party's data privacy. Federated learning stands in contrast to the typical centralized machine learning, where the training data needs to be collected and centralized for training. Requiring the parties to share their data compromises the privacy of that data!
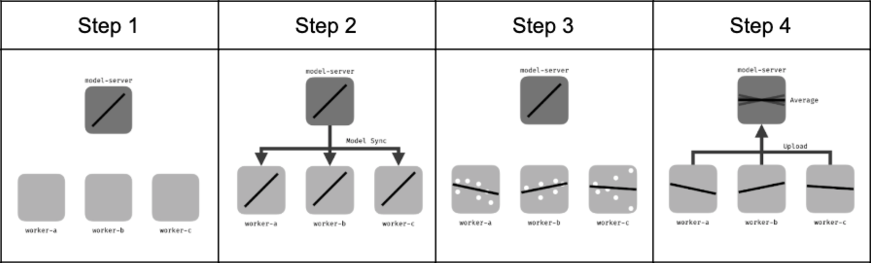
In federated learning, model training is decentralized and parties do not need to share any data. This process is generally broken into four steps:
A central server who is coordinating the model training starts with an initial trained model.
The central server transmits the initial model to each of the data holders.
Each data holder conducts training with the model on their own data locally.
The data holders send only their training results back to the central server, who securely aggregates these results into the final trained model.
A diagram showing the basic training process under federated learning. Adapted from Wikimedia Commons under CC-BY SA.
Note that while federated learning is the primary topic of this challenge, there are many other privacy-enhancing technologies, such as differential privacy, homomorphic encryption, and secure multi-party computation. These technologies can be complementary and used together with federated learning and with each other. In fact, we expect successful solutions in this challenge to leverage multiple privacy-enhancing technologies in interesting and novel ways!
Here are some additional general resources about federated learning:
Federated learning produces a global model that aggregates local models obtained from distributed parties. As data from each participating party does not need to be shared, the approach provides a baseline level of privacy. However, privacy vulnerabilities exist across the FL lifecycle. For example, as the global federated model is trained, the parameters related to the local models could be used to learn about the sensitive information contained in the training data of each client.
Similarly, the released global model could also be used to infer sensitive information about the training datasets. Protecting privacy across the FL pipeline requires a combination of privacy-enhancing technologies and techniques that can be deployed efficiently and effectively to preserve privacy while still producing ML models with high accuracy and utility.
You will design and develop end-to-end solutions that preserve privacy across a range of possible threats and attack scenarios, through all stages of the machine learning model lifecycle. You should therefore carefully consider the overall privacy of your solution, focusing on the protection of sensitive information held by all parties involved in the federated learning scenario. The solutions you design and develop should include comprehensive measures to address the threat profiles described below. These measures will provide an appropriate degree of resilience to a wide range of potential attacks defined within the threat profile.
LIFECYCLE
You should consider risks across the entire lifecycle of a solution including, in particular, the following stages:
Training
Raw training data should be protected appropriately during training
Sensitive information in the training data should not be left vulnerable to reverse-engineering from the local model weight updates.
Prediction/inference
Sensitive information in the training data should not be left vulnerable to reverse-engineering from the global model. The privacy solution should aim to ensure that those with access to the global model cannot infer sensitive information in the training data for the lifetime of the model’s production deployment.
ACTORS AND INTENTION
You should consider threat models that range from honest-but-curious to malicious, applied to both aggregators and participating clients, and propose solutions accordingly. While participating organizations can be trusted, such threat models help capture a broad spectrum of possible risks, such as the outsourcing of computation to the untrusted cloud; and, in the event trusted private cloud infrastructure is used, the remaining possibility that malicious external actors could compromise part of that infrastructure (for example one or multiple banks), leading to a potential reduction in the trustworthiness of components within the system.
PRIVACY ATTACK TYPES
Any vulnerabilities that could lead to the unintended exposure of private information could fundamentally undermine the solution as a whole. You should therefore consider a range of known possible privacy attacks, and any new ones relevant to the specific privacy techniques you employ or to the specific use case. You will primarily be expected to consider inference vulnerabilities and attacks, including the risks of membership inference and attribute inference.
Instructions
Abstract instructions
You must complete two submissions. The first submission will be a one-page abstract, followed by a concept paper. Abstracts will be screened for competition eligibility and inform challenge planning for future stages. Feedback will not be provided.
ABSTRACT REQUIREMENTS
Successful abstracts shall include the following:
Submission Title The title of your submission
Solution Description A brief description of your proposed solution, including the proposed privacy mechanisms and architecture of the federated model. The abstract should describe the proposed privacy-preserving federated learning model and expected results with regard to accuracy. Successful abstracts will outline how solutions will achieve privacy while minimizing loss of accuracy.
ABSTRACT STYLE GUIDELINES
Abstracts must adhere to the following style guidelines:
Abstracts must not exceed one page in length.
Abstracts may be submitted in PDF format using 11-point font for the main text.
Set the page size to 8.5”x 11” with margins of 1 inch all around.
Lines should be at a minimum single-spaced.
A template is provided here that you may choose to use. Abstracts can be submitted through the abstract submission page.
Concept paper instructions
The second and primary submission for this phase is a concept paper. This paper should describe in detail your solution to the tasks outlined in the financial crime prevention or pandemic forecasting tracks. Successful papers will clearly describe the technical approaches employed to achieve privacy, security, and accuracy, as well as lay out the proof-of-privacy guarantees.
You should consider a broad range of privacy threats during the model training and model use phases. Successful papers will address technical and process aspects including, but not limited to, cryptographic and non-cryptographic methods, and protection needed within the deployment environment.
There may be additional privacy threats that are specific to your technical approaches. If this applies, please clearly articulate how your solution addresses any other novel privacy attacks.
You are free to determine the set of privacy technologies used in your solutions, with the exception of hardware enclaves and other specialized hardware-based solutions. For example, any de-identification techniques, differential privacy, cryptographic techniques, or combinations thereof could be the part of the end-to-end solutions.
CONCEPT PAPER REQUIREMENTS
Successful submissions to the Phase 1 concept paper competition will include:
Title The title of your submission, matching the abstract.
Abstract A brief description of the proposed privacy mechanisms and federated model.
Background The background should clearly articulate the selected track(s) the solution addresses, understanding of the problem, and opportunities for privacy technology within the current state of the art.
Threat Model This threat model section should clearly state the threat models considered, and any related assumptions, including:
the risks associated with the considered threat models through the design and implementation of technical mitigations in your solution
how your solution will mitigate against the defined threat models
whether technical innovations introduced in your proposed solution may introduce novel privacy vulnerabilities
relevant established privacy and security vulnerabilities and attacks, including any best practice mitigations
Technical Approach The approach section should clearly describe the technical approaches used and list any privacy issues specific to the technological approaches. Successful submissions should clearly articulate:
the design of any algorithms, protocols, etc. utilized
justifications for enhancements or novelties compared to the current state-of-the-art
the expected accuracy and performance of the model, including, if applicable, a comparison to the centralized baseline model
the expected efficiency and scalability of the privacy solution
the expected tradeoffs between privacy and accuracy/utility
how the explainability of the model might be impacted by the privacy solution
the feasibility of implementing the solution within the competition timeframe
Proof of Privacy The proof of privacy section should include formal or informal evidence-based arguments for how the solution will provide privacy guarantees while ensuring high utility. Successful papers will directly address the privacy vs. utility trade-off.
Data The data section should describe how the solution will cater to the types of data provided and articulate what additional work may be needed to generalize the solution to other types of data or models.
Team Introduction An introduction to yourself and your team members (if applicable) that briefly details background and expertise. Optionally, you may explain your interest in the problem.
References A reference section.
If the use of licensed software is anticipated, please acknowledge it in your paper.
CONCEPT PAPER STYLE GUIDELINES
Papers must adhere to the following style guidelines:
Papers must not exceed ten pages in length, including abstract, figures, and appendices. References will not count towards paper length.
Before submitting your paper, please ensure that it has been carefully read for typographical and grammatical errors.
Papers must be submitted in PDF format using 11-point font for the main text.
Set the page size to 8.5”x 11” with margins of 1 inch all around.
Lines should be at a minimum single-spaced.
A template is provided here that you may choose to use. Concept papers can be submitted through the concept paper submission page. Note that the concept paper submission form will not be enabled until your team's abstract has been screened by challenge organizers.
Evaluation and Submission
Evaluation criteria
The concept paper will be evaluated according to the following criteria, in order of importance:
Privacy Has the concept paper considered an appropriate range of potential privacy attacks and how the solution will mitigate those?
Innovation: Does the concept paper propose a solution with the potential to improve on the state of the art in privacy enhancing technology? Does the concept paper demonstrate an understanding of any existing solutions or approaches and how their solution improves on or differs from those?
Efficiency and Scalability Is it credible that the proposed solution can be run with a reasonable amount of computational resources (e.g., CPU, memory, storage, communication), when compared to a centralized approach for the same machine learning technique? Does the concept paper propose an approach to scalability that is sufficiently convincing from a technical standpoint to justify further consideration, and reasonably likely to perform to an adequate standard when implemented?
Accuracy Is it credible that the proposed solution could deliver a useful level of model accuracy?
Technical Understanding Does the concept paper demonstrate an understanding of the technical challenges that need to be overcome to deliver the solution?
Feasibility Is it likely that the solution can be meaningfully prototyped within the timeframe of the challenge?
Usability and Explainability Does the proposed solution show that it can be easily deployed and used in the real world, and provide a means to preserve any explainability of model outputs?
Generalizability Is the proposed solution potentially adaptable to different use cases and/or different machine learning techniques?
Submissions
Abstracts should be submitted through the abstract submission page. You will also need to answer additional questions about your team and solution. You may use a template for the abstract, which you can find here.
Concept papers should be submitted through the Concept Paper Submission page. You may use a template for the concept paper, which you can find here. Note that the concept paper submission form will not be enabled until your team's abstract has been screened by challenge organizers.
Submissions will be reviewed and validated by NIST staff or their delegates, who may request clarification or rewriting if documents are unclear or underspecified.
Keep in mind: only teams who submit a concept paper will be eligible to participate in Phase 2: Solution Development. For more details see the Challenge Rules.
Final registration is now open to join red teams, which will rigorously test the strength of privacy protections of the most promising solutions in the final phase of the challenges. Those interested in participating as red teams must complete registration by December 2.









{kind=link}