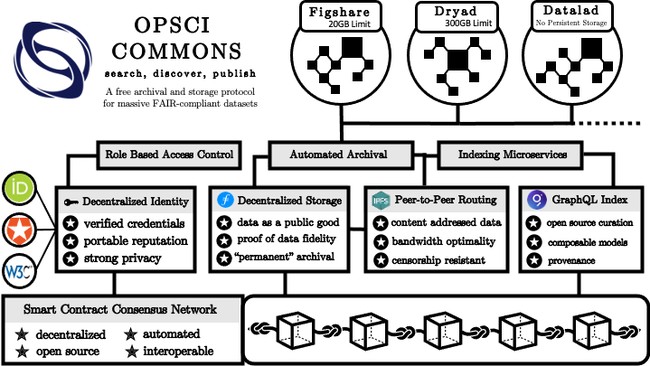
OpSci Commons is a data repository providing free archival, indexing, search, and discovery for massive FAIR-compliant neuroimaging datasets. Commons is a permanent home for open access datasets such as Neurovault, and ABIDE. We built this service for the neuroscience community to provide a free and streamlined UX solution for archiving and sharing large datasets. Commons is a decentralized application (dApp) that executes open source workflows on a distributed network of nodes that ensure tamper-free consensus, content addressed data, verified deterministic results, and no-single point of failure. Since launching, some archived data has actually disappeared from original indices, leaving the only copies to be found on OpSci Commons.
The OpSci Commons team came together during the 2020 Brainhack, where we tackled the problem of peer-to-peer sharing of neuroimaging datasets using IPFS. Our team is composed of data engineers and neuroscientists and we demonstrated how existing neuroinformatics tools can smoothly integrate with peer-to-peer file sharing protocols as an alternative to centralized web storage platforms. Our team is quite diverse, with individual contributors from India, Indonesia, Bulgaria, Romania, Germany, the United Kingdom, Canada, and the United States.
At the start, our team opened up contribution to anyone on the internet. We created a Decentralized Autonomous Organization, OpSci DAO, to coordinate these distributed contributors. The DAO model provides tools for governance, establishes transparency, and incentivizes work in the form of "permissionless" bounties. In many ways, we were the very first Open Data Cooperative, where anyone in the world can contribute to Open Science. Our primitive model was successful, and just one of the first of many, and more sophisticated, Science DAOs. Key to this model is the embracement of Open Source community practices using smart contracts to mitigate disputes, trust, and automate workflows.
OpSci is a pioneer in designing decentralized autonomous organizations (DAO) for science. DAOs make it possible for anyone, anywhere, to get involved by completing bounties, tasks, and solving outstanding problems in a science community. Think of Science DAOs as digital community spaces for coordination and collaboration around research problems. Despite no direct institutional or academic support, our core group of independent researchers, developers, and open science activists has come together with over 1000+ others to build community-owned decentralized protocols that advance science through increased inclusion, access to resources, and transparent governance. The DAO model has potentially significant consequences for how we, as a globally-distributed community of scientists, can coordinate around challenging problems. The most important message we have for other researchers is that impactful science is a collaborative art and that significant discoveries are most likely to occur in communities were access to, and governance over, resources is made open access.