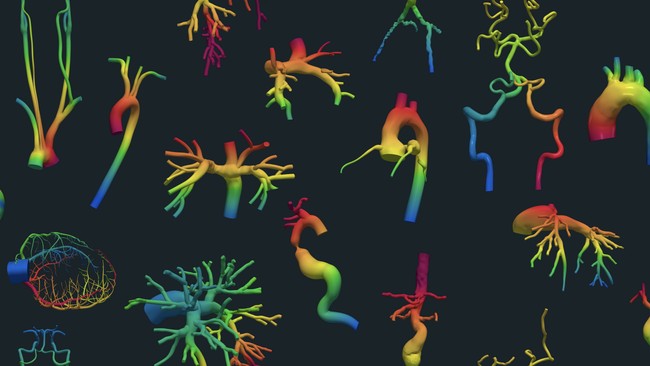
The Vascular Model Repository (VMR) is the largest publicly available repository of cardiovascular anatomic models. The data is stored as project files compatible with SimVascular, the only open-source software providing a complete pipeline from medical image to 3D model generation and blood flow simulation. Nowadays, these computational tools have become critical in surgical planning, personalized treatment planning, testing of novel surgical approaches, and medical device development. We currently host 107 patient-specific models that can be freely downloaded from the VMR website. We are planning on doubling the number of data sets in the coming months by incorporating models created at Stanford University and by our user community.
The VMR was originally created in 2013 within the Open Source Medical Software Corporation (OSMSC). Since 2019, the VMR is funded by NIH grant 5R01LM013120-03 and it is the product of a joint effort between the Marsden lab at Stanford University, the Shadden lab at the University of California Berkeley, and OSMSC founder and UCLA professor Nathan Wilson. Important drivers that brought the group together in its current configuration are the SimVascular project, which is common to all members of the VMR team, and the need to develop a complete database of the cardiovascular models processed within the Stanford and Berkeley labs. As the number of publicly available models on our platform increases, we are planning on opening submissions to other research groups. The core development team of the VMR is composed of members of the Marsden lab, who work on the backend and frontend of the website. Within the Marsden lab, data technician Brian Wu is actively working on gathering data and ensuring that all models uploaded to the VMR website are properly de-identified and meet the quality standards of the data already available. The continuous development of the VMR and its website is coordinated in monthly meetings with the whole team.
The team in its present form was put together at the end of 2019. One of the main goals of the project is the dissemination of cardiovascular data in the spirit of open science. The models in the VMR have been used in the past to develop and test novel surgical approaches for pediatric and adult cardiovascular disease using SimVascular. By enabling the cardiovascular community to reuse this data, we aim at fostering advancements in the field of blood flow simulations with Artificial Intelligence and Machine Learning. Ultimately, our goal is to increase the potential for use of computational methods in the clinical setting by, for example, eliminating the need for human interaction during the model generation stage (currently, one of the bottlenecks of the simulation pipeline) and improving the accuracy of existing reduced order models for close-to-real-time approximation of quantities of interest.
Our philosophy of data sharing is based on the FAIR (Findability, Accessibility, Interoperability, Reusability) principles. Each model in the dataset is associated with its own unique URL (F and A). Moreover, the models organization is based on a variety of categories (e.g., patient age, sex, associated diseases) to allow for easy access based on the users needs (F). Although the models are stored in a format compatible with SimVascular, many of the files contained in each project can be processed with other pieces of software if required (I and R): e.g., image data can be visualized in medical image software and computational meshes can be used in other fluid dynamics solvers. Moreover, the data is copyrighted but distributed under license allowing for its unlimited use for research and development purposes (R).
Among these principles, we believe that findability and reusability of data are particularly important, especially to ensure the reproducibility of simulation results whenever such models are used in research papers.
A compelling aspect of our approach is that models are distributed in the form of SimVascular projects. This is beneficial for two reasons. Firstly, the possibility of opening and inspecting each project directly into SimVascular—instead of relying on different pieces of software for image visualization, segmentation and simulation—makes for a seamless user experience. Secondly, less experienced users can learn about each step of the pipeline from image data to fluid simulations by examining projects generated by experts.
The VMR leverages two of the most popular guidelines for data sharing: the FAIR and CARE principles.
Being associated with a publicly accessible website with direct links to data with globally unique and persistent identifiers, the VMR satisfies the first two core concepts of FAIR: findability (F) and accessibility (A). Moreover, the models and their metadata in the VMR use formal and accessible language as well as data formats widely used in the field of cardiovascular simulations, in accordance with the interoperability (I) and reusability (R) principles.
Similarly, the VMR follows the CARE principles to respect any data recorded from indigenous populations. The purpose of the VMR is collective benefit (C) through easy access and standardization of cardiovascular simulation data for further improvement in the field of biomechanics. The VMR team recognizes the responsibility (R) and ethics (E) related to the data sharing by ensuring that patient data is properly de-identified, to enforce confidentiality and prevent harmful use.
Our data sharing model is suitable to be adopted by other research groups in academia and industry with access to large datasets. Important steps to replicate it are: (i) assigning members within the team to quality checking and de-identification of available data (if necessary), (ii) the creation of a platform (e.g., website) to easily navigate and download data, and (iii) the use of URLs or DOIs to unambiguously identify elements in the dataset.
The benefits of data sharing are vast. Not only does it encourage collaboration between researchers, but data sharing also helps make scientific discovery more efficient by not wasting resources on repeating existing research. For example, through the Vascular Model Repository (VMR), we have collaborated with clinicians and research scientists to generate novel breakthroughs in modeling cardiovascular systems.
Along with scientific collaboration, data sharing also allows for machine learning (ML) research on large datasets. By amassing models that were generated for prior publications into the world’s largest public database, the VMR allows for training and testing on ML networks which will lead to faster medical image segmentations and improved simulations.
Finally, data sharing opens the door to many pedagogical avenues. By giving public access to a multitude of cardiovascular models and simulations, we help instructors teach new students how to analyze cardiovascular simulations as well as how to build models to produce their own future work.
The response from the community to the new website's launch 6 months ago has been positive. Since then, we have had more than 1700 visitors from around the world with over 2000 downloads.
