Neurodegenerative diseases pose a significant burden in the U.S. and worldwide [Ref. 1 in Supporting Document 1]. There are currently very few effective treatments [2] and therapeutic development is costly and time-consuming [3].
There is growing interest in identifying drug combinations rather than monotherapies due to the potential for enhanced efficacy while reducing adverse effects [4]. Indeed, the use of Donepezil and Memantine has been shown to increase the 5-year survival rate of Alzheimer’s disease patients [5].
We propose creating an open source, interactive platform for researchers to computationally test the efficacy of their own drug combinations called DRAGON. It will leverage Zenodo datasets in a network-focused approach, while integrating clinical trial data for broader utility. Overall, this project aims to facilitate the discovery of new therapeutics for neurodegenerative diseases and deepen our understanding of the molecular mechanisms driving neurodegeneration.
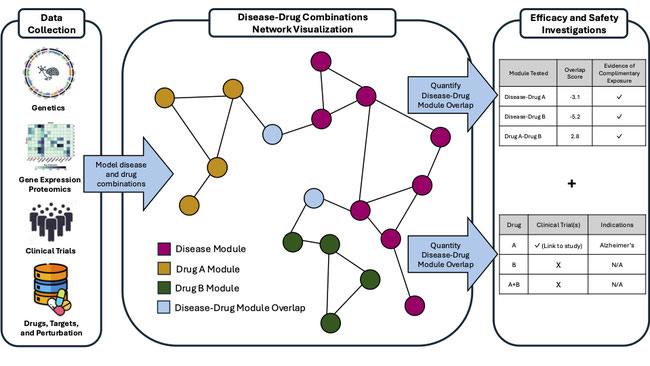
The DRAGON project will identify novel drug combinations for neurodegenerative diseases by performing 3 complementary but distinct analyses (Aims 1A, 1B, and 2) and make these findings publicly available for researchers to test their own combinations (Aim 3). Specifically:
Aim 1A: To create and visualize 5 neurodegenerative disease modules and 768 drug modules from publicly available datasets.
We will apply the approach in [6] to create 5 neurodegenerative disease modules and 768 drug modules. Briefly, we will first create a background “brain network” using protein-protein interaction (PPI) data [7] and GTEx Consortium data [8] from Zenodo (3.2 MB csv and a 6.6 MB .gct files, respectively). Then, we will subset the brain network to high confidence disease-associated genes to create the disease modules and subset the direct target information to make drug modules [6,9, see GREI Repository section and Supporting Document 2 for more information]. We chose disease associations from diverse populations whenever available. While we are inherently constrained by the quality of the data already collected, the success of this approach in accelerating psychiatric drug development to human trials is compelling [10]. Finally, we will visualize these modules using visNetwork [11].
Aim 1B: To rank 3.32 million prospective drug combinations by their measure of complementary exposure.
Many FDA-approved drug combinations demonstrate complementary exposure, where each drug targets a different pathway important for the disease [6]. To assess complementary exposure, we will calculate the module overlap values ([termed Z-values and S-values in 6, 10]) of all possible disease-drug combination pairings from the modules created in Aim 1. We will rank combinations based on these values. Work on Aims 1A and 1B has already begun using R on AWS and will be finished by January 2025.
Aim 2: To contextualize the drug combinations in Aim 1 by integrating clinical information.
Some well-ranking combinations in Aim 1B may have been tested in clinical trials individually for a neurodegenerative disease, or individually or in combination for another disease. We will extract and organize publicly available clinical trial data from the Clinical Trials Transformation Initiative on Zenodo [12; 586 MB of .txt files] for these drugs in a data table in R so that it is easy to search and understand. Work from this Aim will be completed by February 2025.
Aim 3: To develop an open-source, interactive platform with the findings from Aims 1-2, empowering researchers to explore and prioritize novel drug combinations for their neurodegenerative disease(s) of interest.
By hosting the results of Aims 1-2 on the DRAGON platform (via shinyapps.io [13, Supporting Document 3]), it will be ready for out-of-the-box use for neurodegenerative researchers worldwide by the end of May 2025. We will submit our Phase II application in early June 2025 and aim to submit a preprint to bioRxiv by December 2025.
Neurodegenerative diseases, such as Alzheimer’s, affect millions worldwide, yet treatment options remain limited [1-3]. Through the DataWorks! Prize, we will create DRAGON (Drug Repurposing Analysis and Generation Of Novel Molecular Combinations), an open-source, interactive platform to address major challenges in drug discovery. By allowing researchers to propose and explore novel drug combinations, DRAGON will help expand treatment options for neurodegenerative diseases.
After selecting a specific disease and two drugs, DRAGON will perform three secondary analyses and display the findings. Each analysis offers distinct yet complementary outputs that aid in identifying and prioritizing drug combinations.
Expected outputs from Aim 1A are the visualization of disease and drug modules. These outputs will aid researchers by showing the disease-associated genes (and their connections) as well as the drug targets and their first neighbors for molecules of interest, including the biologically-meaningful overlap of these modules [6]. This display will also show any drug overlaps, which may influence safety and efficacy [4]. Overall, these outputs will allow a deeper understanding of neurodegenerative disease and drug mechanisms.
Aim 1B will output module overlap scores related to the proposed drug combination's complementary exposure with the disease and to each other [6]. Effective drug combinations, like those for hypertension [6] and psychiatric diseases [10], are more likely to show scores for complementary exposure, improving assessment of the combination’s efficacy.
The output of Aim 2 will be a table with information as to whether or not the drug combination or individual drugs selected have been tested in clinical trials for any indication [12, 14, 15]. If so, the trial information, including clinical trial identifiers and indication(s) tested, will be displayed. This information will be helpful for drug repurposing efforts, as it can provide safety information as well as prior evidence of efficacy and mechanistic insights for a disease of interest [4, 14, 16].
DRAGON will adhere to FAIR principles. Findability will be ensured by providing DOIs and registering datasets in Zenodo. Accessibility will be achieved through an open-access platform with comprehensive documentation, available via a publication and a workflowR site [17, 21]. Outputs from Aims 1-2, along with the DRAGON platform developed in Aim 3, will be hosted on shinyapps.io with the corresponding code on GitHub [20, Supporting Document 3]. Interoperability will be facilitated through standardized formats ensuring compatibility with other datasets and tools. Version-controlled datasets posted on Zenodo will ensure reproducibility in the data and analysis pipelines.
In conclusion, this project will significantly contribute to neurodegenerative drug discovery by creating accessible, reproducible, and actionable outputs.
The proposed project has significant implications across pharmacology, neuroscience, and computational biology. By leveraging network biology to identify and test drug combinations for neurodegenerative diseases, it bridges the gap between theoretical models and clinical efficacy in drug discovery.
DRAGON seeks to impact how therapies for neurodegenerative diseases are identified. Most current treatment strategies are single-agent therapies [14], which may fail to address the subphenotypes involved in these conditions. By identifying synergistic drug combinations with complementary mechanisms, DRAGON has the potential to improve therapeutic efficacy, reduce adverse effects, and enhance patient outcomes [4]. The integration of clinical trial data allows for a more robust evaluation of combination therapies or when considering adjuvant treatments [15].
The proposed project addresses a critical gap in current open-access research tools, which often focus on in depth details of individual studies rather than facilitating the aggregation of studies related to disease-drug pairings. In contrast, the DRAGON platform will provide a centralized, open-source platform accessible to all researchers, enabling them to easily locate data on drug combinations, biological networks, and clinical trial information. Researchers will also be able to utilize DRAGON’s findings and methodologies, facilitating additional secondary analyses and promoting exploration of novel drug combinations to accelerate drug development.
By ensuring DRAGON’s code, stored on GitHub and organized in workflowR [17], is accessible and reusable, researchers will be able to leverage its visualizations, calculations, and data integrations. These tools can be applied not only to neurodegenerative diseases but also to discover drug combinations in other disease-relevant tissues. For example, computational approaches like this are vital for developing treatments for diseases with limited human in vivo data available, such as rare diseases [16].
By addressing the complex interplay of biological networks and drug interactions, DRAGON can pave the way for novel therapeutic strategies that improve patient care and advance understanding of the molecular mechanisms underlying these diseases. It will facilitate a quicker translation of hypothesized drug combinations into real-world treatments for neurodegenerative diseases.
Our team comprises of 2 PhD-level scientists with expertise in statistical genetics, collectively authoring 13 peer-reviewed journal articles and 2 provisional patents in this area. Additionally, one member is an author on a USPTO-issued patent that employs the complementary exposure approach proposed here to identify new drug candidates for psychiatric disorders [10]. Our team members have worked together for over 7 years, including the successful completion of the NSF I-Corps program in 2018 [18] and the University of Chicago’s SPARK grant program. With an additional combined six years as Statistical Geneticists in industry with experience in drug discovery, the team has contributed to projects spanning from preclinical research to Stage 2b clinical trials. Notably, two drugs we contributed to during the preclinical phase are now actively being tested in clinical trials (Trial Identifiers: NCT05922878, NCT06502964).
Our expertise in reproducible research is a core asset of our team. The R code for many of our research projects are available on GitHub [19, 20] and we provide detailed documentation for this code through workflowR sites [21]. The team’s workflowR sites have been used to teach genomic analysis in other labs, including at the University of Texas Medical Branch at Galveston. Finally, we also have substantial experience with Shiny for data visualization and interactive applications, ensuring that this team is well-equipped to drive the success of this proposal.
We believe that DRAGON will succeed due to our collaborative team of experts in statistical genetics and neuroscience drug discovery, the key advancements made with this secondary analysis approach in psychiatric diseases (of which one team member was significant contributor [10]), the integration of valuable clinical trial data insights, and the potential for broader research applications beyond brain diseases.
While It is possible that our network biology-based approach may not identify new combinations or those successful in trials may not show complementary exposure, previous work suggests this is unlikely [6, 10]. Regardless of these findings, the DRAGON platform will still provide disease and drug network visualization and clinical trial data integration, which are informative for researchers.
Note: All references for this proposal are listed online in Supporting Document (1).
Additional information about disease and drug datasets are listed online in Supporting Document (2).
