Accurately predicting diseases from genetic data is crucial for realizing precision medicine. Polygenic score (PGS), a machine-learning model trained on large-scale human genetic data, attracted substantial interest. However, the inequitable predictive performance of PGS models across population groups and the limited interpretability of the prediction models remain the key challenges. Here, we address those limitations via a secondary analysis of publicly available datasets. Specifically, we will integrate the inclusive polygenic score model (iPGS), a recently proposed model for genetic prediction for genetically diverse cohorts, and integrate the iPGS models with functional genomic resources. We will provide the results of the secondary analysis and integrated analysis platform as an interactive web browser, allowing clinical scientists to explore and possibly integrate interpretable genetic risk score models in basic and clinical research to advance precision medicine.
Our proposal addresses the interpretability of polygenic score (PGS) models through secondary analysis of publicly available data in the GERI repositories. Specifically, we focus on the challenge of interpreting the PGS models, which may contain thousands or millions of genetic variants, and integrate them with existing functional genomic datasets to improve the interpretation. We will provide the results as an interactive web resource on the iPGS browser (https://ipgs.mit.edu/) and deposit the underlying associated data to the GREI repository.
Aim 1: Integrate sparse polygenic scores with functional genomic resources
Polygenic scores often contain a large number of genetic variants. For clinical applications, enhancing the explainability of the underlying mechanisms of genetic variant effects is critical. To that end, we will integrate the sparse polygenic score resources (flat table files, DOI list for polygenic score models is in the GREI Repository Dataset section) and functional genomic resources, for example, computationally predicted transcriptional factor binding sites (UCSC bed file format, DOI: 10.6084/m9.figshare.12774539). We will expand the analysis and integrate resources generated by other researchers.
Aim 2: Graphical user interface for statistical overrepresentation analysis for biological interpretation
To increase confidence in biological interpretation, it would be helpful to conduct a statistical evaluation of the overrepresentation of functional genomic features to genetic variants included in the PGS models. To that end, we will implement statistical overrepresentation analysis in an interactive web application. We will use a variant of GREAT enrichment and PRSet analyses.
Aim 3: Systematic integration for developing biologically-guided polygenic score
It is important to ensure that the genetic prediction models benefit everyone regardless of their demographic background, such as genetic ancestry groups. We will leverage the integrated functional genomic resources to further improve the transferability of polygenic scores. Specifically, we hypothesized that large-scale integration of functional genomic annotations enhances PGS transferability, as each annotation captures different mechanisms. We will apply transfer learning (1) to learn the annotations of genetic variants through the optimal combination of genomic annotations and (2) to incorporate the genomic annotations in PGS model training. Specifically, we will expand the penalized regression in the inclusive polygenic score (iPGS) modeling framework and adjust the levels of penalization of each genetic variant when fitting the PGS model. We will assess the improvements in predictive performance and provide the results in the web resources.
Timeline
We have already started on Aims 1 and 2 and envision having the results in the next 3 months. For Aim 3, we have started implementing the PGS analysis pipeline and envision having substantial results in the next 6 months.
Our proposal will result in an expanded atlas of interpretable and inclusive polygenic score (PGS) models. Specifically, we will expand the inclusive polygenic score (iPGS) browser (https://ipgs.mit.edu/) and disseminate the results through the platform.
Aim 1: Biological interpretation on the browser
On the iPGS browser, we currently show basic information (e.g., gene symbols) of the top genetic variants included in the PGS model (Fig. 1). We will augment this resource and allow the researchers to investigate the functional genomic resources (e.g., transcription factor binding sites and histone modification status) in an interactive manner.
Aim 2: Statistical overrepresentation analysis
For statistical overrepresentation analysis, we will implement the graphical user interface so that users can conduct a downstream statistical analysis for biological interpretation within the web application. This removes the need for researchers to download data and install software packages. The functionality will allow researchers with less technical backgrounds, such as clinical scientists, to engage in the biological interpretation of PGS models.
Aim 3: Biologically-guided polygenic score
We will release the PGS models trained with biological information in the browser. We will compare the new model vs. the standard approach and quantify the improvements in predictive performance.
FAIR and CARE principles
In PGS analysis, most analysis pipelines rely on summary-level information computed for pre-defined population groups (e.g., European, African, South Asian, and East Asian). They are not applicable to individuals of admixed ancestry. We have recently developed an inclusive polygenic score (iPGS), the first PGS methodology applicable to all individuals across the entire continuum of genetic ancestry groups. We demonstrated that ancestry-inclusive PGS training improves the predictive performance across population groups, most notably with an average of 60% improvements in African populations. We will use the iPGS models as much as possible to ensure the results and benefits of the genomics research benefit everyone regardless of demographic and genetic background.
We will map the phenotypic data in the polygenic scores to standard ontology terms using experimental factor ontology (EFO) so that the PGS models are findable. The resulting PGS models will be distributed under a CC-BY 4.0 license, addressing the accessibility. The PGS models will be in a standard flat table format, and we will provide clear documentation addressing the interoperability and reusability of the resources.
Figures
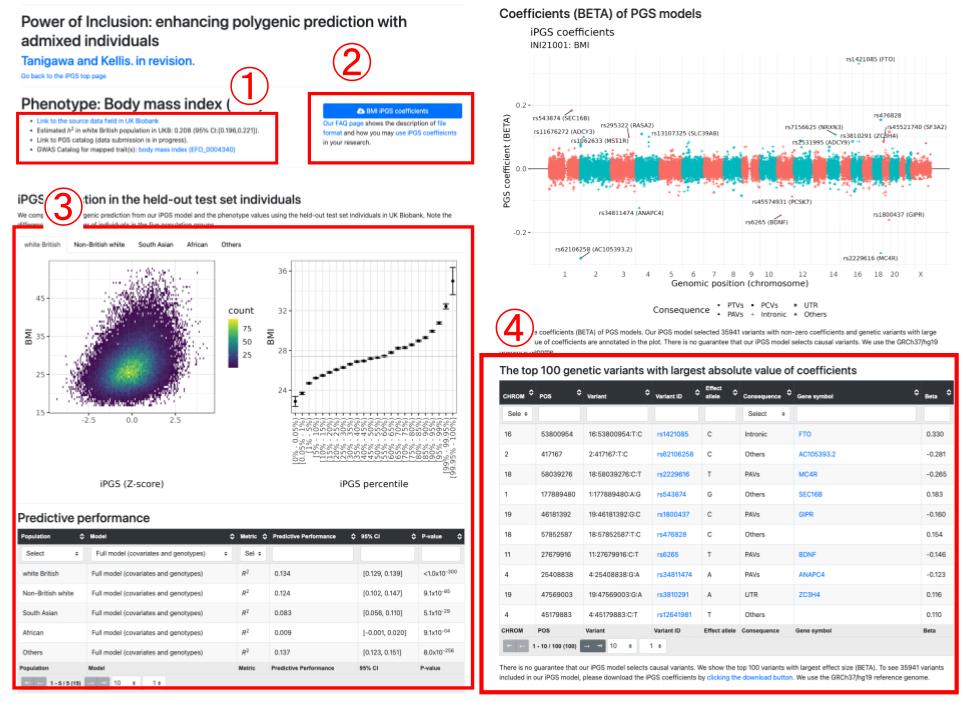
Figure 1. A preliminary version of the iPGS browser. (1) We describe the metadata and link to external resources via ontology mapping (experimental factor ontology, EFO). (2) The Dataset download button. (3) summary-level information on the predictive performance of PGS models. (4) A sortable and filterable table describing the genetic variants selected in the model.
Accurately predicting diseases from genetic data with polygenic scores (PGS) allows more efficient risk stratification in the population and transforms disease prevention and treatment. On the one hand, the predictive performance of PGS models has substantially improved in the last decade, thanks to the increasing sample size in population-based cohorts with genetic data and the methodological innovations in machine learning, statistical modeling, and artificial intelligence. On the other hand, the limited interpretability of the black-box predictive models and inequitable predictive performance across individuals from genetically diverse backgrounds remained key challenges in translating the advancements in PGS research into clinical deployment. Our proposal focuses on the emerging opportunities for secondary analysis of existing data. We will develop a web platform to streamline integrative analyses, allowing clinical researchers to explore the biological interpretation of the predictive models. Combined with the inclusive polygenic scores (iPGS), which improve the predictive performance across genetically-diverse individuals, the resulting resource will provide interpretable genetic risk models applicable to everyone across the entire spectrum of genetic ancestry. We anticipate that the interdisciplinary research community, including genetic epidemiologists, cardiologists, and computational biologists, will benefit from the expected outcomes. The developed resources will help tailor risk screening and disease prevention in epidemiology and help infer genetic predisposition for specific disease mechanisms, allowing tailored treatment accounting for individuals’ genetic profiles.
Our team consists of three members with experience in human genetics, genomics, and web application development.
Yosuke Tanigawa, Ph.D.
Dr. Tanigawa has substantial research experience in computational biology and statistical genetics, as reflected in more than 30 original research publications. He has led the methodological development and systematic application of polygenic scores. Recently, he developed the inclusive polygenic score (iPGS). He also has experience working on functional genomic analysis, including the computational prediction of transcription factor binding sites and statistical overrepresentation analysis to pathway annotations. He received the MIT Open Data Prize 2024 and was featured in a case study on the use of NIH Figshare. He will be in charge of the methodological design, web application updates, and project coordination. The demonstrated track record experiences position him as an ideal leader for the proposal.
Xiaohe Tian
Ms. Tian holds an M.S. from Harvard University and is currently a Ph.D. student at Cornell University. She has substantial research experience in bioinformatic analysis and statistical genetics. Ms. Tian will be in charge of integrating functional genomic resources and polygenic score models.
Our team has already started working on the development and expansion of the inclusive polygenic score resources. For example, we currently take the publicly available polygenic score models generated as a part of our prior studies (DOIs: 10.1016/j.ajhg.2023.09.013 and 10.1016/j.ajhg.2024.09.008) and available at generalist repositories (DOIs: 10.6084/m9.figshare.22905368 and 10.17605/OSF.IO/CEB7G). The initial version of the browser was developed by Dr. Tanigawa, and the most recent update was deployed on Oct 22nd, 2024. Ms. Tian and Dr. Tanigawa have already worked on an integrative analysis of polygenic scores and publicly available resources, using functional genomic resources generated by consortia studies. Dr. Tanigawa has been working on incorporating the results for the future updated browser release. Those ongoing efforts ensure the successful execution of the proposal, and additional resources from the 2024 DataWorks! Prize will further accelerate systematic integration.
