Large Language Models (LLM’s) are employed in scientific workflows to streamline data collection and analysis. AI agentic systems refined for specialized datasets can reduce AI hallucinations. The Molecular Analysis and Reasoning Assistant (MARA) (Nanome Inc), is a scientific discovery copilot utilizing LLM’s for workflows in biochemical informatics. MARA is capable of accessing chemical databases, visualizing and manipulating chemical structures, processing tabular data, identifying chemical analogs, downloading structural files, and visualizing molecular structures. Users can extend the functionality of MARA by building custom tools which can be collected into workflows. For instance, we built a python based tool to get the IUPAC name of a compound based on its common name using the PubChem API. Our goal to build tools to access the API’s of the GREI databases, allowing data in those repositories to be accessible in MARA.
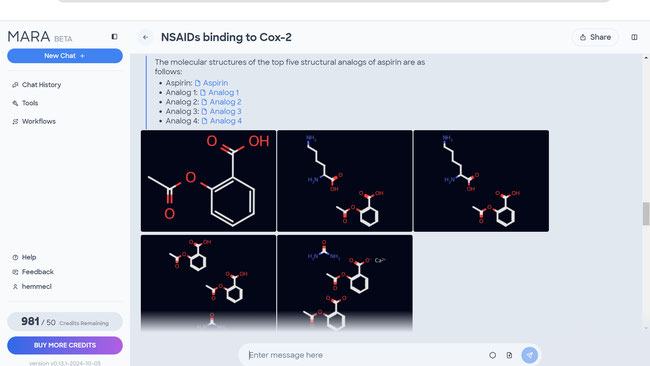
Kamakia et al (https://f1000research.com/articles/12-444) conducted a virtual screening of analogs of common nonsteroidal anti-inflammatory drugs (NSAIDs) using a variety of tools to explore the pharmacodynamic and pharmacokinetic properties of the drugs when bound to COX-1 and COX-2 proteins. In summary, the researchers submitted SMILES strings for the reference drugs to SwissSimilarity to identify analogs which were docked to COX-1 and COX-2 structures downloaded from the RCSB database. SMILES strings of the analogs were submitted to SwissADME and Protox II databases for toxicity and pharmacokinetic property determination.
MARA is an ideal platform for automating and expanding this workflow. MARA has built-in capabilities for downloading structures from RCSB and for identifying chemical analogs. Additional functionality can be built in using custom tools to access SwissDrugDesign tools such as SwissSimilarity. Our research aims are as follows:
The primary outcome of the work will be to create a general workflow that can replicate the types of analysis conducted in the Kamakia analysis and extend it to any similar system. The secondary outcome is to create functionality to allow for incorporation of GREI repository data into MARA workflows. This will allow for rapid LLM-assisted assessment of drug-protein interactions and comparison of results with data in GREI and other repositories. These workflows will be useful not only for analysis of new drugs but also secondary analysis of existing datasets such as may be found in the GREI databases.
A criticism of LLM’s is that they often act as black boxes. MARA outlines in detail the steps taken for each query, allowing the user to better understand the underlying logic the LLM is using. This contributes significantly to reproducibility. The analyses will follow FAIR data principles by making any tools or code developed in this project accessible to the public. Tools developed in MARA include the code/database queries used. Any tools and workflows generated will be publicly available through MARA and the RI-INBRE Molecular Informatics Core GitHub page. The use of MARA also contributes to interoperability as the secondary goal is to incorporate access to all GREI databases into MARA allow for simplified data access, comparison, and reporting and reuse of GREI datasets.
The fields of pharmacology and in silico drug design are being rapidly transformed by the development of artificial intelligence tools. AI tools such as Deep Mind's AlphaFold have made it possible to rapidly predict structures of nearly any molecule, leading to a massive increase in the number of potential drug targets that can be analyzed. Similarly, AI agentic systems such as MARA are vital for streamlining and expanding the cheminformatic workflows necessary for large scale molecular assessment of potential drugs and their targets. These workflows are useful not only for analysis of new drugs, but also for secondary analysis of existing drugs. PubMed currently lists over 500 manuscripts related to drug repurposing and AI/ML. Given the massive size and complexity of existing biomedical databases, AI agentic systems are essential tools for such secondary analyses.
By developing tools and workflows in MARA, we can simplify and streamline the process of data collection and collation from multiple repositories including PubChem, ChEMBL, and the GREI databases. Simple pharmacological analysis workflows such as described in the Kamakia dataset can be automated and tested for accuracy, and then expanded to allow for new functionality. Once validated, tools developed for accessing other GREI repositories through MARA will allow rapid identification of other similar datasets in those repos which can be themselves analyzed. Using the extended reality functionality of the Nanome app, researchers can easily visualize and share their results in XR with collaborators in real time.
Dr. Christopher L. Hemme has a PhD in Biochemistry and has been a bioinformatician for 25 years. He is currently a Research Associate Professor in the Department of Biomedical and Pharmaceutical Sciences in the College of Pharmacy at the University of Rhode Island and serves as the Director of the RI-INBRE Molecular Informatics Core (MIC). The work proposed here is in line with the goals and mandates of the MIC as outlined in the RI-INBRE grant P20GM103430.
Dr. Abdeltawab Hendawi is an assistant professor in Computer Science and Data Science at the University of Rhode Island (URI). He is the Co-director of the AI-Lab at URI. He received his PhD in Computer Science from the University of Minnesota (UMN). His research interests are centered on big data and AI with a focus on smart cities and smart health related applications. His research is sponsored by grants from NSF, TIDC, and USDA.
