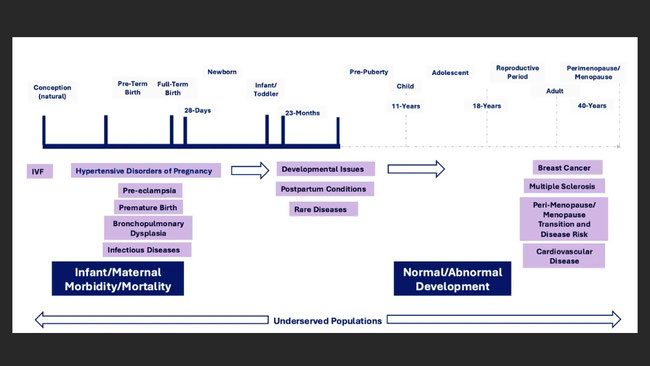
Fifty percent of all US women are 40 or older and either perimenopausal or menopausal. This normal transition is poorly understood by clinicians, especially as women may experience similar symptoms but are progressing through this transition in a personalized manner. This leads to individual risk for breast cancer, cardiovascular disease, etc. Most studies focus on identifying risk factors using statistically based methods, including AI/ML. Our preliminary studies show that understanding an individual’s physiologic development may be more accurate and move correlative analysis to causality. We have been developing “model-driven” analytics that focus on identifying the causal basis for risk and disease and support the potential to diagnose early. This approach focuses on developing physiologically based models of a woman’s developmental journey and then examines available data sources to populate and evaluate the model. We integrate data across public and GREI repositories.
There are considerable efforts, resources and investments dedicated to the generation and collection of data across diverse technologies, condition, populations, etc. In parallel, advances in computational approaches and technologies are driving the use of methods based in AI/ML as well as other advanced statistical analyses. While these can produce great insights, most of these results remain correlative rather than causal, and in healthcare causality is critical to be able to identify develop actions to enhance prevention, diagnosis, treatment, and outcome.
Data Sources and Types
We will use data from the UK Biobank, All of Us, SWAN, Women’s Health Study, Longitudinal Women’s Health in Australia, SEER, etc., which provide extensive information on women’s health, genetics, and postmenopausal outcomes. The project will leverage variables such as age at menarche, age at first birth, gestational age at birth, reproductive history, and incidence of chronic diseases, etc. Additionally, multiple datasets from GREI repositories will be incorporated, focusing on reproductive history and postmenopausal health. The GREI datasets will complement the cohort data by providing additional detail on gestational history, parity, and other reproductive factors critical for modeling women’s health trajectories.
Methods and Analysis
We will be applying methods that include our novel algorithms for next generation phenotyping that examines progression over time along with both advanced statistical analysis including AIML when appropriate to evaluate not only the significance of individual factors but, more importantly, their interactions.
Timeline
Our preliminary efforts have involved parallel development of the model and “qualification” of individual databases to fill gaps. This project will form the basis for a long-term evolving study, both identifying new data for collection as well integrating new databases. Significant results will be achieved within the first 12 month period.
Research Findings and Expected Outcomes
We believe that, as outlined in the Research Aims, there will be at least two separate but critical outcomes from the research: 1) exploration of the use of model-driven analysis for secondary data analysis that will be generalizable, and 2) a deeper understanding of how lifelong physiologic development impact’s a woman’s transition through perimenopause and menopause and results in individualized risk for breast cancer, cardiovascular disease, and osteoporosis.
We intend to communicate the research findings of both aims in appropriate journals that focus on modeling as well as clinical journal and conferences, etc. We have initiated these activities in collaboration with several underserved women’s groups to support the model development and have established channels for reporting back the results of our studies.
To ensure replicability, all analysis pipelines, including data preprocessing, model training, and evaluation processes, will be documented in detail and made available through open-source platforms. The use of publicly available datasets such as UK Biobank and All of Us will facilitate replication since these resources are accessible to other researchers, ensuring transparency.
The primary clinical outcome of this project will be how physiologically based modeling can provide a deeper understanding of how reproductive milestones—such as age at menarche, age at first birth, gestational age, and menopause timing—affect the risk of postmenopausal diseases, particularly breast cancer and cardiovascular disease. By utilizing longitudinal data and causal modeling techniques, we expect to identify common physiological development trajectories that lead to personalized disease risk. These findings will provide actionable insights for clinicians to better support women through perimenopause and menopause, potentially leading to earlier interventions and personalized treatment plans.
The study will also generate a robust model that integrates multiple physiological time-based variables to predict postmenopausal health risks. The model and results will be designed to offer clinical utility, improving the understanding of women's health trajectories and informing both healthcare professionals and patients.
The outcome of our research into model-driven analytics as secondary data analysis will serve as a complement to current AI/ML based data-driven modeling.
FAIR and CARE Principles
We will adhere to the FAIR principles by ensuring that the datasets, models, and code we produce are well-annotated, stored in searchable repositories, and shared under appropriate licenses for broad reuse.
The CARE principles will be adhered by collaborating with diverse and underrepresented communities, ensuring that data sharing and research results align with the benefit of those populations.
We believe that this project will have unique impact in a significantly underserved health area while simultaneously establishing the value of applying model-driven analytics to secondary data analysis as a major complement to current data-driven methods, e.g. AI/ML.
In example, as referenced above, the current data-driven algorithms for breast cancer risk assessment commonly utilize SEER data as a primary source and carry out statistical analysis of the database with updated algorithms implementing AI/ML approaches. In the predominant Klaus and Cuzick-Tyler models, a key factor is “whether a breast biopsy, either positive or negative, has been done.” Although this is statistically significant, over 15 years of informal surveying, we have yet to identify any woman who has undergone a breast biopsy who did not believe she was at significant risk for breast cancer. These models are statistically correct but contain a significant bias that impacts their true utility in clinical practice.
By contrast, in the model-driven approach, we are studying one factor that involves the age of last pregnancy and its potential overlap with the start of perimenopause. In perimenopause, a woman is experiencing a down-regulation of estrogen/estradiol response but in pregnancy the fetus generates a 1,000-fold excess of estradiol. Thus the potential that this may impact the mother’s normal perimenopause/menopause transition and post-menopausal disease risk is now focusing on potential causality, not simply correlation.
An additional impact of the model-driven approach is the ability to identify critical data that may not be collected in current databases, but is necessary to address specific clinical questions. This issue is generalizable beyond our current study as it reflects on the reality that any database is naturally reflective of existing knowledge/expectations of what is critical data and therefore may contain unrecognized biases. It is understandable that the collection of data is time and resource intensive and this drives data collection to focus on “what is most relevant or accessible.” Acknowledging that our current understanding of disease, and even normal development such as the perimenopause-menopause transition, is somewhat limited, it is important to consider methods that will support stretching our current boundaries.
Michael N. Liebman, Ph.D (theoretical chemistry and protein crystallography) is the Managing Director of IPQ Analytics, LLC and Strategic Medicine, Inc. His research focuses on computational models of disease progression that stress risk detection, disease processes and clinical pathway modeling, and disease stratification from the clinical perspective. He utilizes systems-based approaches and design thinking to represent and analyze risk/benefit analysis in pharmaceutical development and healthcare and reimbursement.
Sasha Rieders is a data scientist at IPQ Analytics. Her research has focused on applying analytical methods to improving public health outcomes. She worked as a research statistician for 3 years.
The opportunity to interact with clinicians, clinical researchers, and database developers across clinical and data science disciplines to identify what data should be collected at the time of the design of the data repositories.
