Scales measuring life events, such as The Holmes and Rahe Social Readjustment Scale and its current adaptations, focus on widespread events and often lack sensitivity required for contemporary individuals and population groups. Our recent review showed that research only uses commonplace events, such as getting divorced, while ignoring events crucial for immigrants (such as forced displacement) or for non-binary individuals, to name a few examples.
Stressful life events are important for a range of mental health issues, suicidal behaviour, and a range of physical conditions. Our recent project demonstrated that some events, such as losing a home or getting arrested, act as significant barriers to vital cancer screenings.
Our project proposes to leverage natural langauge processing and datasets based on Reddit’s depression forum, and similar, to update stressful events collections. The insights gained will be invaluable in enhancing the scientific understanding of stress and its impact.
1. Research Aims:
• The primary aim of this project is to update the existing scales of stressful life events to add modern realities and minority-specific events. By doing so, we hope to enhance the relevance of these scales in health research and practice.
• We will reuse datasets based on Reddit data, such as depression and suicidewatch subreddits, as our main data source. These subreddits are repositories of real-world experiences related to mental health struggles, providing unfiltered access to discussions of unique life challenges, situations, and stressful events. Our preliminary analysis showed these datasets include unique information, for example, related to discrimination and bullying, that needs to be systematically collected for future use in research and clinical practice
• The secondary aim of this project is to provide quantifyable measures of the new stressful events captured. This will enable us to understand which events are more widespread. We understand that platforms, such as Reddit, have a unique demographic composition, not generalizable to the whole population. We will mention this limitation when publishing our frequency statistics. Some subreddits are dedicated to minority groups, if we identify those in GREI repositories ad-hoc we will reuse them, as they are an important source of information on stressful events.
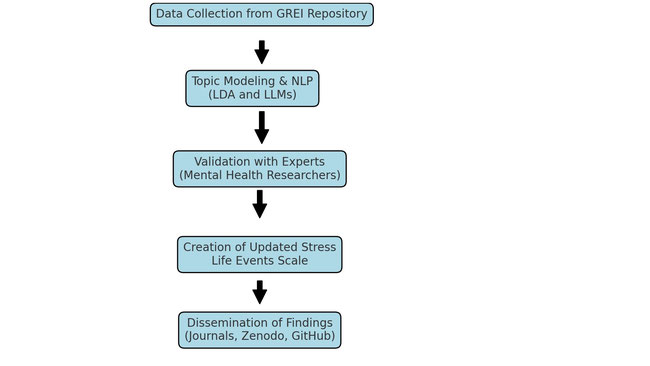
2. Data Utilization:
• In compliance with the requirements of this challenge, we will also incorporate data from the Generalist Repository Ecosystem Initiative (GREI). The primary dataset for this project contains over 6000 Reddit posts from the depression and suicidewatch subreddits. However, we plan to identify and reuse additional similar datasets coming from other sources (for example, twitter data related to depression and suicide). An additional depression-related dataset derived from 43 subreddits can be found in another GREI repo. We believe there is plenty of data in GREI ecosystem that we can reuse for our project.
3. Methods:
• We will apply topic modeling using Latent Dirichlet Allocation (LDA) and large language models (LLMs) to identify new and relevant stressful life events, particularly those affecting minority populations. We will experiment with different values of K (number of topics) to capture a nuanced and high-level group of events. We will experiment with different LLM prompts to ensure their sensitivity.
• We will collect information on how many times each event was mentioned to build frequency statistics on how often each type of event or event group is mentioned
• After making a preliminary collection of events, we will consult our mental health and trauma healthcare team to help us group and standardize events (for example, discrimination based on ethnicity or gender might be grouped in a single block "discrimination")
• The project is projected to span 4-6 months, with 1-2 months for modeling and analysis, 2 months for validation, and 1-2 months for reporting.
Research Findings
The primary outcome will be an updated scale of stressful life events, focusing on those relevant to minority populations. The findings will highlight previously underrepresented stressors, contributing to more effective health interventions.
Dissemination
Findings will be published in open-access journals, presented at relevant academic conferences, and shared through public health forums. In addition, we will disseminate our findings on platforms like Zenodo, Figshare, and pertinent other repositories to ensure that the data and results are freely accessible to the wider scientific community.
FAIR & CARE Principles
All datasets, analyses, and findings will be assigned persistent identifiers (e.g., DOIs) to ensure long-term discoverability. We will document the sources of data clearly (i.e., GREI repository datasets) and the methodology used, ensuring that researchers and practitioners can easily locate our work. The documentation and codebase related to data processing and analysis will be shared openly on platforms like GitHub to provide full transparency and facilitate access.
Reproducibility
We will provide the code used for our secondary analysis on GitHub, ensuring that others can replicate and build upon our work.
Scientific Contribution
The project will significantly enrich our understanding of how stressful life events are evolving, particularly for minority groups. By addressing gaps in current stress scales, this research can help create a more inclusive approach to mental health support.
Impact on Diagnosis, Treatment, and Prevention
These scales will be used by our biomedical informatics team in research on stressful life events to assess how they impact a wide range of health outcomes: from cancer screening adherence to mental health problems.
We will work also with our software team to enrich our electronic health records system to support the assessment of a larger range of life stressors, paying particular attention that minority stressors are adequately collected.
The updated life event scales will enable health professionals to make more accurate diagnoses, particularly in underrepresented populations.
Our interdisciplinary team comprises health informatics professionals and NLP experts with extensive experience in secondary data analysis. We successfully collaborated on previous projects involving large-scale data collection, topic modeling, and LLMs.
Our team consists of
Dr. Dmitry Scherbakov (team captain) - third-year postdoc in biomedical informatics with a strong interest in mental health disparities and how to use data science methods to address them.
Dr. Paul Heider (NLP consultant) - Assistant professor of biomedical informatics, our NLP brain and expert, with industry experience and background in linguistics.
Dr. Jihad Obeid (social determinants and NLP consultant) - Associate professor of biomedical informatics, our lead on social determinants of health data availability in electronic health records.
Key considerations for the success of this project include ensuring ethical data collection and anonymization processes, addressing potential biases in the data, and validating the relevance of identified life events through consultation with mental health professionals.
