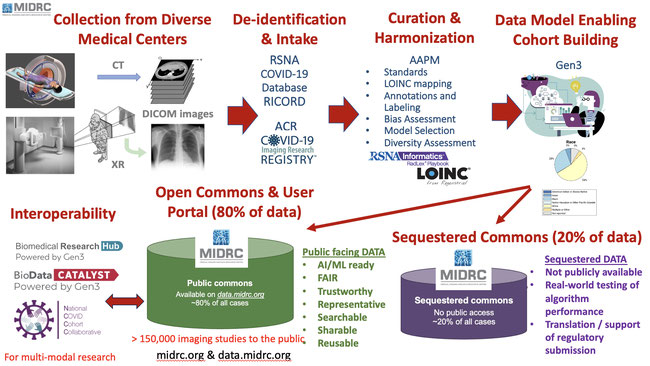
MIDRC, the Medical Imaging and Data Resource Center, is a collaborative multi-institutional effort to create a publicly-sharable representative and diverse image repository/commons to accelerate medical imaging machine intelligence research as well as a sequestered commons for performance evaluation and benchmarking of algorithms. MIDRC is co-led by the American Association of Physicists in Medicine (AAPM), the Radiological Society of North America (RSNA), and the American College of Radiology (ACR), and is hosted at the University of Chicago, and resides on the Gen3 data ecosystem. (midrc.org and data.midrc.org) MIDRC data are harmonized and vetted by clinical, machine learning/AI, and data science domain experts and are aligned with a common data model. The public open data commons was created “at scale” and is interoperable with other data commons to enable multi-modal, multi-omics research as well as rigorous statistical evaluations. MIDRC also has a user portal for cohort building, allowing for multiple re-uses of the data by various AI developers for various specific tasks. MIDRC has ingested over 300,000 imaging studies (from over 130,000 people) and has released free to all researchers, over 145,000 medical imaging studies. All of MIDRC’s SOPs, data models, data harmonization, annotation, and data management strategies are publicly available.
For a given medical image:
--- A patient has already benefited through medical care.
--- A hospital/medical center has already benefitted through reimbursement.
--- Now let the public benefit with the MIDRC second sharing & usage of the images.
--- You can help change the culture of medical imaging
The imaging and metadata are public and open to all researchers. The public data portal allows user-friendly methods for cohort building. Downloading of data are described through various monthly seminars, townhalls, help sheets, and newsletters. MIDRC has developed a graph data model that is implemented in Gen3. MIDRC Gen3’s Graph Database’s schema is strictly defined by the MIDRC Gen3 Data Dictionary (which is a series of nodes, properties, and relationships). The Gen3 API QA/QC’s any addition to the graph during the submission process and does not allow non-conforming data to be added. The data model is modular, expandable, scalable (more organs, modalities, diseases). QA/QC is done through creation of SOPs and tracking SOP adherence for data processing. Additional QA/QC is completed through data processing and examination. Compliance is enforced through acceptance, rejection or requiring resubmission of data.
MIDRC data resides on the Gen3 data ecosystem, yielding FAIR principles in collection, curation, and sharing. MIDRC data have findability and accessibility (via the search and download at the MIDRC data portal at data.midrc.org). MIDRC interoperates with other data repositories having demonstrated real time interoperability with BioData Catalyst and with N3C. All the open data and various resources are available to researchers enable reuse of data and of technical developments.
MIDRC data collection includes 2 real world data ingestion channels through professional medical imaging societies: the American College of Radiology (ACR) and the Radiological Society of North America (RSNA). This top-down model has facilitated access into multiple clinics nationwide that are now funneling data into MIDRC. Through MIDRC’s data science subcommittees, the various organizations and investigators collaborate to create representative data models, to allow for use of LOINC mappings for harmonization of the imaging data, and user-friendly portal for efficient cohort building and downloading. MIDRC has developed a unique annotation pipeline which automates the generation of labels for any potential medical image dataset with minimal human expert intervention. This incorporates large language models to create high quality "pre-labels" and "helper-AI" tools that work to harmonize metadata values. Semi-supervised computer vision ensembles are used to link the prelabels with discrete imaging features.
MIDRC ingests, stores, and shares DICOM medical images over multiple time points and modalities, as well as JSON files of clinical and demographic metadata (such as race, ethnicity, sex, age, geographic, COVID status, and image acquisition parameters). Resources include online help documents, metrology decision tree, and bias definitions and bias mitigation processes, as well as Jupyter notebooks for expediting cohort building and downloading, and for file conversion (such as DICOM to png), and with appropriate APIs, MIDRC enables interoperability with other data commons.
MIDRC has aimed to solve the following problem in ML/AI, thus enabling advances in the discipline of AI/ML. Basically, approximately 80% of the critical challenges to developing unbiased and trustworthy AI for clinical endpoints as well as for biomedical discovery are the data, which need to be diverse, curated, harmonized, and open, with a portion of the data sequestered for testing and translation. The data need to be cleaned and vetted by clinical, machine learning/AI, and data science experts and be aligned with a common information model. These data commons need to be created “at scale” and interoperable with other FAIR data commons to enable multi-modal, multi-omics research as well as rigorous statistical evaluations. If these important challenges are not met, then much of the future (as is current) machine learning/AI research and development will be wasted efforts, yielding biased algorithms that will not be generalizable for real world applications. Without having such a scalable and diverse open commons, the development will be restricted to those who could afford data. An open public commons levels the playing field for all, allowing for diverse & representative data as well as diverse investigators. Without the addition of sequestered data, testing and translation will not be effective and not be efficient.
Relevant references to support your assertions
https://www.nature.com/articles/s42256-021-00307-0
https://www.ncbi.nlm.nih.gov/pmc/articles/PMC8017381/
https://www.bmj.com/content/369/bmj.m1328
MIDRC is a multi-institutional collaborative initiative driven by the medical imaging community that was initiated in late summer 2020 to help combat the global COVID-19 health emergency. MIDRC is aimed at accelerating the transfer of knowledge and innovation in the COVID-19 pandemic and beyond. MIDRC, funded by the National Institute of Biomedical Imaging and Bioengineering (NIBIB) and hosted at the University of Chicago, is co-led by the American College of Radiology® (ACR®), the Radiological Society of North America (RSNA), and the American Association of Physicists in Medicine (AAPM). The aim of MIDRC is to foster machine learning innovation through data sharing for rapid and flexible collection, analysis, and dissemination of imaging and associated clinical data by providing researchers with unparalleled resources.
The collaborative teamwork has enabled the collection of real-world imaging data at a level never seen before – in terms of quality and efficiency, thus enabling advanced research at new speeds and volume. MIDRC has already ingested over 300,000 imaging studies, of which over 145,000 imaging studies have been released free to all researchers.
The data sharing and reuse ability with MIDRC data is expected to have a catalytic impact on both AI/ML research, at scale (through the use of the open commons), and on the validation and translation of developed algorithm (through the use of the sequestered commons).
MIDRC is only in its third year of creation, and it has already ingested over 300,000 imaging studies, of which over 145,000 imaging studies have been released free to all researchers. It is expected that research conducted with MIDRC data, as well as with other commons through interoperability, will reach new heights, especially with the additional resources that MIDRC freely supplies.
MIDRC may be the cleanest and largest medical imaging commons.
As new imaging modalities and as new clinical use cases are tackled by investigators MIDRC can be easily extended. Additional use cases could be stood up by the recruitment of additional biomedical domain experts to work with the machine learning/AI and data commons experts to extend data intake sites, data models, data curation & harmonization, and appropriate user portals and to acquire additional data storage capabilities, i.e., scaled incrementally based on compelling biomedical use cases. In addition, all of our SOPs, data models, and data management strategies are publicly available. Researchers who want to replicate our overall approach can learn from our work on data modeling, data harmonization, image de-identification, annotation, and data organization.
Researchers now can freely search, build cohorts, and download imaging and meta data via the MIDRC user portal at data.midrc.org. Researchers can also contribute their data to MIDRC, either from their clinical repositories or from their NIH research grant (via the NIH Data Management and Sharing policy). Investigators can also now freely access and use the various MIDRC resources to enhance their AI research including a metrology decision tree and a bias awareness tool, as well as various algorithms and parameter sets on MIDRC’s public GitHub.
We already promote MIDRC through various monthly seminar, townhalls, newsletters, and presence at RSNA, AAPM, and SPIE meeting. We will extend our presence to other scientific societies, thus broadening the ability of MIDRC to grow and diversify further as well as extend the usage of MIDRC to others.
We can grow and extend MIDRC to additional imaging modalities and additional clinical use cases. Additional use cases could be stood up by the recruitment of additional biomedical domain experts to work with the machine learning/AI and data commons experts to extend data intake sites, data models, data curation & harmonization, and appropriate user portals and to acquire additional data storage capabilities, i.e., scaled incrementally based on compelling biomedical use cases.
A peer can begin as many others have already – at midrc.org and at data.midrc.org. MIDRC already has 522 registered users from 369 institutions/companies. For example, in the past 30 days, MIDRC has had 272 unique user sessions, almost 190,000 downloads, and over 42 TB of downloads.
NIBIB specified that MIDRC be co-led by AAPM (American Association of Physicists in Medicine; PIs are Maryellen Giger from the University of Chicago and Paul Kinahan from the University of Washington), ACR (American College of Radiology; PIs are Mike Tilkin and Charlie Apgar from ACR), and RSNA (Radiological Society of North America; PIs Curt Langlotz from Stanford and Adam Flanders from Jefferson) along with Gen3 (PI Robert Grossman), and MIDRC Central administration and finance led by Katherine Pizer from the University of Chicago. MIDRC is hosted at the University of Chicago and exists on the Gen3 data ecosystem. The infrastructure, governance, and management of the scalable data commons have been under development since August 2020 for the use cases of acute COVID and long COVID. However, it is now also available for non-COVID cases. MIDRC started with four technology development projects (TDPs) to create the infrastructure and twelve collaborative research projects (CRPs) to jumpstart various research projects. MIDRC then created four data science subcommittees of DPP (Data Policy and Procedures led by ACR), DSIT (Data Standards and Information Technology led by RSNA), DQH (Data Quality and Harmonization led by AAPM), and DSUP (Data Search and User Portal led by Gen3). While these are led by the different organizations, they are run with members from all the organizations to allow for cross fertilization of the four TDPs; enabling a significant collaborative effort. In addition, the MIDRC members also run four Work Groups: the Grand Challenge Work Group, the Bias and Diversity Work Group, the Annotation and Labeling Work Group, and the Validation and Regulatory Work Group. This infrastructure allows for a free, curated, ML-ready data commons as well as various free resources to enhance AI research including a metrology decision tree and a bias awareness tool, as well as various algorithms and parameter sets on MIDRC’s public GitHub. And MIDRC has continued, active engagement of NIBIB staff and leadership.
