Calling all coders, gamers, race fans, and drone enthusiasts
Launching the AlphaPilot Innovation Challenge, Lockheed Martin and The Drone Racing League (DRL) have challenged teams of coders, engineers, and technologists to take on developing artificial intelligence (AI) for high-speed racing drones.
Of over the 420 teams that applied in 2019, only 9 finalists earned the opportunity to compete in mastering autonomous flight and win more than $1,250,000 in cash prizes.
The AlphaPilot challenge tests teams of up to 10 participants on their ability to design an AI framework - powered by the NVIDIA Xavier GPU for autonomous systems - capable of flying a drone through three-dimensional race courses using only machine vision and guidance, navigation, and control algorithms. Teams will not have prior knowledge of the exact course layouts, nor will they benefit from GPS, data offboarding, or human intervention of any kind. Designed by DRL, the autonomous drone will provide the sensing, agility, and speed needed for competitive racing as part of DRL’s new Artificial Intelligence Robotic Racing (AIRR) Circuit, starting in fall 2019.
Why Drones?
Drone racing is a futuristic sport and a big draw for millennials and K-12 students with an interest in technology — many of whom will become future STEM professionals, drone pilots, and engineers. Lockheed Martin recognizes the important role in helping to develop a workforce with skills to compete in a 21st century high-tech economy. Lockheed Martin and DRL targeted U.S. undergraduate and graduate students to apply for AlphaPilot; however, the competition was open to drone enthusiasts, coders and technologists of all ages from around the world.
Why is Lockheed Martin doing this?
For more than 100 years, Lockheed Martin has been redefining flight — from the fastest speeds, to the edge of space, to unmatched maneuverability, and stealth. AI-enabled autonomy promises to fundamentally change the future of flight, and we are actively developing disruptive new AI technologies that will help our customers accomplish their most important missions – from reaching Mars to fighting wildfires.
ABOUT LOCKHEED MARTIN
Headquartered in Bethesda, Maryland, Lockheed Martin is a global security and aerospace company that employs approximately 105,000 people worldwide and is principally engaged in the research, design, development, manufacture, integration and sustainment of advanced technology systems, products and services. For more information, please visit www.lockheedmartin.com/alphapilot.
ABOUT DRONE RACING LEAGUE
DRL is the professional drone racing circuit for elite FPV pilots around the world. A technology, sports and media company, DRL combines world-class media and proprietary technology to create thrilling 3D drone racing content with mass appeal. The 2019 DRL Allianz World Championship Season will feature races in iconic venues across the globe that'll stream on Twitter and Youku and air on the best sports programs worldwide, including NBC, Sky Sports and ProSieben. For more information, please visit www.drl.io
The AlphaPilot Innovation Challenge will push the boundaries of AI “edge computing” far beyond current achievements. It takes humans years to master high-speed, precision drone flight. Lockheed Martin and DRL are aiming to exceed human capabilities in under two years.
The Challenge
The AlphaPilot challenge tests teams of up to 10 participants on their ability to design an AI framework - powered by the NVIDIA Xavier GPU for autonomous systems - capable of flying a drone through three-dimensional race courses using only machine vision and guidance, navigation, and control algorithms. Teams will not have prior knowledge of the exact course layouts, nor will they benefit from GPS, data off-boarding or human intervention of any kind. Designed by DRL, the autonomous drone will provide the sensing, agility and speed needed for competitive racing as part of DRL’s new Artificial Intelligence Robotic Racing (AIRR) Circuit, starting in fall 2019.
This is a competition of AI quality – all other racing variables, including the drone hardware, are controlled.
Prizes
AlphaPilot will award more than $2,000,000 in prizes for its top performers through 2020!
The first AlphaPilot Team to beat a human-piloted drone in head-to-head competition will take home an extra $250,000.
The 2019 AlphaPilot World Champion will take home $1 million.
How can I Participate?
In the program’s inaugural season, AlphaPilot Teams were challenged to a barrage of tests in the Virtual Challenge Qualifier including development of image classification algorithms and performance in simulated racing environments, where their technical strategies were evaluated by a panel of industry experts.
For this year, the final 9 teams have been chosen and the program is now closed to new applicants. To follow the final qualifying teams through the challenge and get the latest news on the 2019 AIRR circuit and 2020 AlphaPilot open applications, hit the “Follow” button in the top right corner.
The 2019 Virtual Qualifier
The 2019 Challenge Qualifier consisted of three different tests of which their combined scores determined who moved forward in the competition.
Test 1: The first component of the AlphaPilot Virtual Qualifier - a series of questions focused around the team’s strategic approach to autonomy programming, tested each team’s knowledge, experience, readiness, and cohesion. The goal was to inspire confidence in the team’s ability to develop novel approaches to drone racing, bring the resources needed to compete, and mitigate real-world uncertainty.
Test 2: The second component of the AlphaPilot qualification focused on machine vision - challenging teams to develop an image classifier algorithm capable of detecting key racing elements. Drone racing requires efficient, low-latency visual processing in order to autonomously navigate through gates at high speeds. Therefore, effective machine vision approaches are critical for teams to be successful at AlphaPilot.
Test 3: The third component of the AlphaPilot qualification focused on a team’s ability to design algorithms for the guidance, navigation, and control of an autonomous drone. This test utilized a simulator framework that provided users with the tools needed to test their drone racing algorithms using realistic dynamics and exteroceptive sensors. These skills are essential for competition in AlphaPilot and the test was considered a precursor to work conducted by finalist teams in preparation for each AIRR race event.
Who can Participate?
Lockheed Martin and DRL have targeted U.S. undergraduate and graduate students to apply for AlphaPilot; however, the competition was open to drone enthusiasts, coders and technologists ages 18+ from around the world. The final qualifying teams in 2019 have come from all across the globe including Sweden, the Netherlands, South Korea, Brazil, Poland, Switzerland, and three different states within the U.S.
AlphaPilot Teams will work with professional mentors and industry-leading technical partners. Lockheed Martin engineers and AI specialists will serve as mentors to AlphaPilot Teams. DRL will supply AlphaPilot teams with standardized drones, and their drone experts will collaborate with teams and Lockheed Martin technical mentors throughout the multi-year partnership. Contestants will also have access to products from NVIDIA, the leader in AI computing.
Over the past few weeks, the rapid spread of COVID-19 and its wide-ranging impacts have caused severe disruptions around the world. The COVID-19 is affecting us all – at work, at home, and in our communities. Lockheed Martin believes that resolving this challenge should take precedent over our other challenge, AlphaPilot. In this spirit, we have decided to cancel our plans for a 2020 season. Health and safety are our top priority. We encourage everyone following AlphaPilot to use the time and effort they would have put into a 2020 season to instead help the world defeat COVID-19. Your creative spark and desire to solve difficult problems is exactly what the world needs right now.
Lockheed Martin would like to thank those who followed and participated in the 2019 season. Together, we accomplished amazing things and brought new energy to the future of autonomous flight. This is not an ending; it’s just the beginning.
The 2019 AlphaPilot and AIRR seasons finished with a head-to-head race between our winning team, MAVLab, and DRL's representative human pilot, Gab707. Through several course runs, MAVLab clocked a best time of 11.5 seconds; shaving a half-second off their winning time from the AIRR Championship. Their top speed was measured at 14.6 miles per hour. Manually piloting the RacerAI drone, Gab707 achieved a 6.9 second finish time, reaching 24.7 miles per hour. Pilot vs. Programmer: Round 1 goes to Gab707...but by a much smaller margin than anticipated!
We hope to build on this friendly competition in 2020 by giving our top programmers another chance to outperform the world's top human drone pilots.
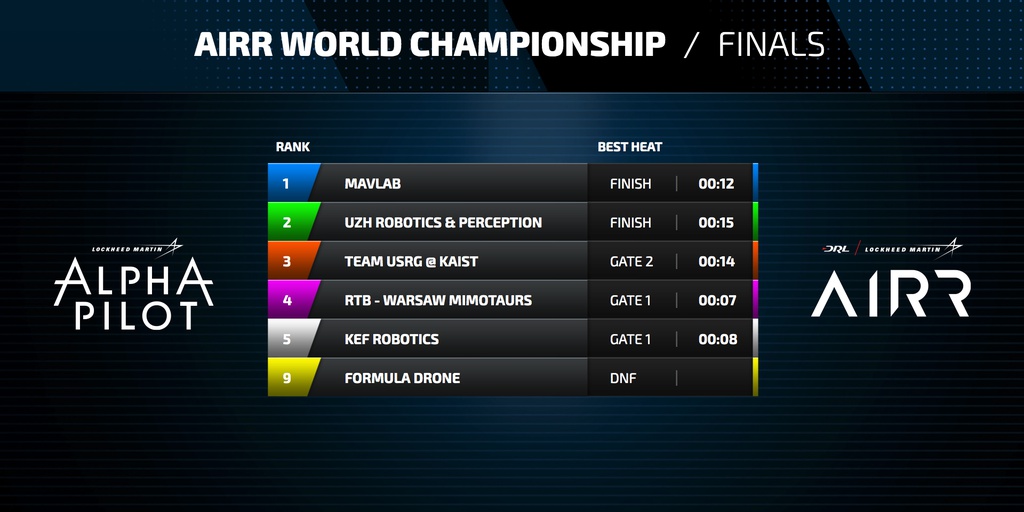
Congrats, Team MAVLab, for taking home the $1,000,000 prize with a winning time of 12 seconds! A tight competition with Team UZH Robotics & Perception, who clocked a best finishing time of 15 seconds.
Lockheed Martin is pleased to recognize Team MAVLab for their fantastic achievement in the 2019 AIRR Season. Selected among 424 team entries in the AlphaPilot Innovation Challenge, Team MAVLab has demonstrated commendable teamwork, agility, and innovation. Lockheed Martin launched AlphaPilot using benefits from the Tax Cut and Jobs Act of 2017. Our goal was to drive innovation and foster the development of cutting-edge AI applications. AI is an exponential technology with great potential benefits for humanity. The rapid progress of 9 Finalist teams over the season is evidence of how quickly technology can advance with the right talent. Together, our teams are helping make history, as we strive to achieve the “Deep Blue Moment” for autonomous flight – outperforming a human drone pilot. Your work is monumental to building a better future.
Thank you, Beemo, for playing at our AIRR World Championship Race! Beemo is an Orlando-based folk band comprised of several Lockheed Martin engineers ....their very own Tony Mickle (base guitar) is a member of the AlphaPilot program team!
Thanks for the great performance and for showing the amazing diversity of our workforce!





.jpg)