Origin of Life is the hardest question in science. No one knows how the first cell came about. But there’s a simpler, more fundamental question: Where did the information come from? An answer will trigger a quantum leap in Artificial Intelligence. This may be as big as the transistor or the discovery of DNA itself. A new $10 million prize seeks a definitive answer.
"Evolution 2.0 is a sign of a shifting emphasis in biology from regarding
life primarily as a chemical system, to looking at the flow of information."
George Church is a geneticist, molecular engineer, and chemist. He is Professor of Genetics at Harvard Medical School and Professor of Health Sciences and Technology at Harvard and MIT, and was a founding member of the Wyss Institute for Biologically Inspired Engineering at Harvard. Developed methods for the first genome sequence. Director, BRAIN Project & PersonalGenomes.org. He is co-author of 509 papers, 143 patent publications & the book "Regenesis". He was also one of Time Magazine’s 100 Most Influential People in 2017.
We have Oxford Professor Denis Noble on board as prize judge and technical advisor. He’s one of the top 100 scientists in the UK. Denis was the first person to build a computer model of an organ. It was the heart. He did this in 1960 using punch cards. His discoveries made pacemakers possible. He is a fellow of the Royal Society. He is editor of the society's journal Interface Focus and he holds a Commander of the British Empire medal from Queen Elizabeth. He organized the Royal Society’s 2016 conference “New Trends in Biological Evolution” in conjunction with the British Academy. He is president of the International Union of Physiological Sciences. Denis is an accomplished musician and pioneer of the field of Systems Biology. He is author of The Music of Life and Dance to the Tune of Life: Biological Relativity.
Michael Ruse
Michael Ruse is a philosopher of science who specializes in the philosophy of biology. He is director of the Program in the Philosophy of the History of Science at Florida State University and author of numerous books including "Darwinism and Design", “The Cambridge History of Atheism” and “Science, Evolution and Religion”. He is well known for his work on the relationship between science and religion, the creation–evolution controversy, and the demarcation problem within science. He is a Fellow of both the Royal Society of Canada and the American Association for the Advancement of Science, and holds honorary doctorates from the University of Bergen, McMaster University, the University of New Brunswick and University College London.
Is $10 Million Enough Money for a Discovery of this Magnitude?
Denis Noble, Perry Marshall and Kevin Ham at the Royal Society
The Mystery
Every cell reproduces itself from digital instructions, stored in DNA. DNA has the same features as modern digital devices: Layers of digital encoding, decoding and data storage; error detection, error correction and repair. Plus an ability to adapt that beggars the imagination.
How do living things repair and heal themselves, adapt to any situation you can imagine, and make choices? The genetic engineering capabilities of cells, which are discussed in the book Evolution 2.0, are not known to most people. But an answer suggests staggering implications for medicine, technology and the environment.
Cells re-engineer themselves, in real time, in hours... even minutes. The reason you have to finish your antibiotics is, germs can hyper-mutate at terrifying speed - then kill you with a vengeance.
How do cells “know” how to evolve? No human software does that. Give software millions of chances and billions of years and all it will do is crash. But life adapts relentlessly. How does it do this? What do cells know that we don’t?
And what about consciousness? In the human realm, only conscious beings create and modify code. Where does consciousness come from? Are cells self aware?
The Evolution 2.0 Prize focuses these issues down to one central question:
How do you get from chemicals to code? How do you get a code without designing one?
Perry Marshall and private equity investment group Natural Code LLC have issued a technology prize to find a person who can solve this.
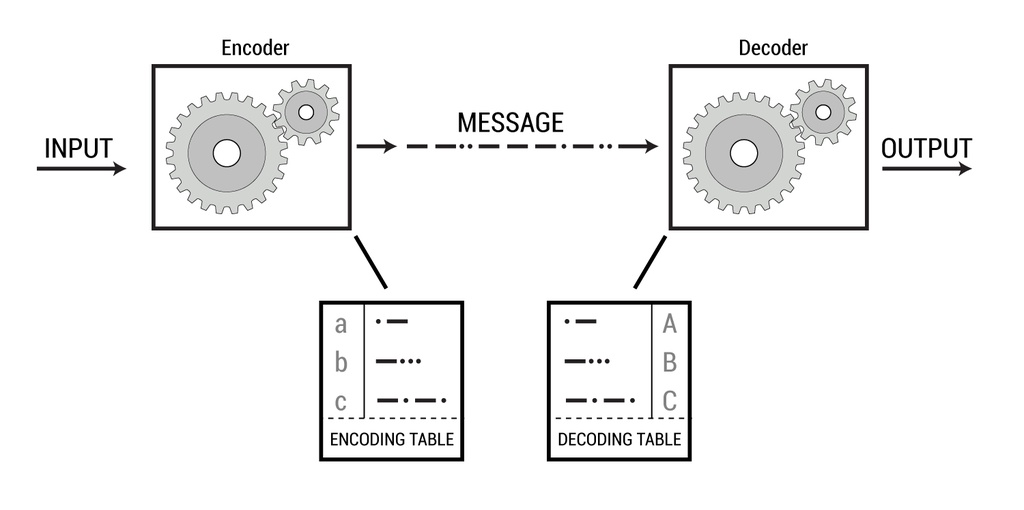
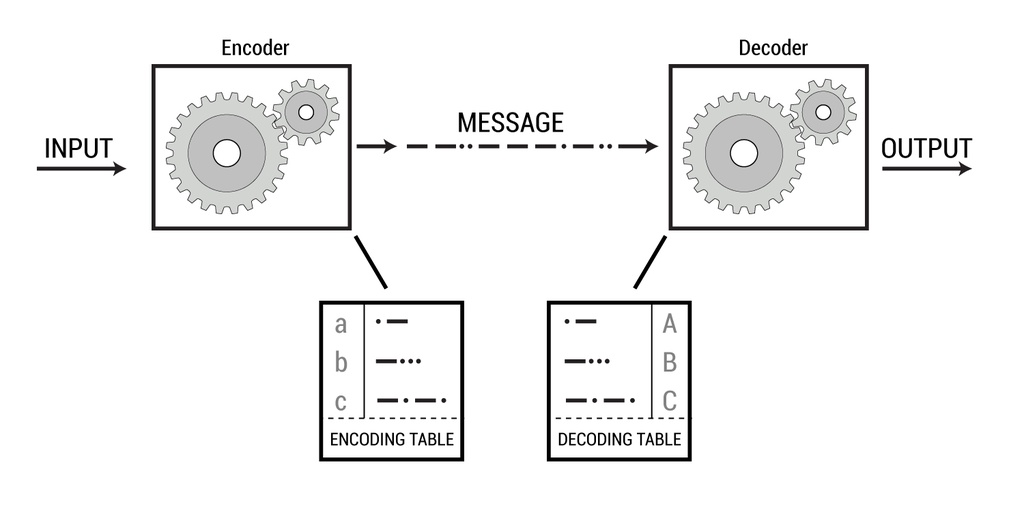
What You Must Do to Win The Prize You must arrange for a digital communication system to emerge or self-evolve without "cheating." The diagram below describes the system. Without explicitly designing the system, your experiment must generate an encoder that sends digital code to a decoder. Your system needs to transmit at least five bits of information. (In other words it has to be able to represent 32 states. The genetic code supports 64.)
You have to be able to draw an encoding and decoding table and determine whether or not the data has been transmitted successfully.
So, for example, an RNA based origin of life experiment will be considered successful if it contains an encoder, message and decoder as described above. To our knowledge, this has never been done.
Does life harness undiscovered laws of physics? Are there unknown emergent properties in nature?
With CRISPR gene editing technology and exponentially accelerating AI, these are questions of burning importance.
If we can unearth the underlying forces that create and propel life, we stand to reap enormous benefits in Artificial Intelligence, engineering, computer science, nutrition, aging, health, cancer research, disease treatment and prevention.
Natural Code LLC is a Private Equity Investment group formed to identify a naturally occurring code. Our mission is to discover, develop and commercialize core principles of nature which give rise to information, consciousness and intelligence.
Natural Code LLC will pay the researcher $100,000 for the initial discovery of such a code. If the newly discovered process is defensibly patentable, we will secure the patent(s). Once patents are granted, we will pay the full prize amount to the discoverer in exchange for the rights. Our investment group will locate or develop commercial applications for the technology.
The discoverer will retain a percentage of ongoing ownership of the technology, sharing in future profits of the company, while benefitting from the extensive finance, marketing and technology experience of our investment group. Prize amount as of May 31, 2019 is $10 million.
Code is absolutely necessary for replication and for life. Code is needed for cells to have instructions to build themselves; code is required for reproduction. Code that has the ability to re-write itself is essential for any kind of evolution to occur.
We define code as a symbolic information passed between an encoder and a decoder (Claude Shannon 1948).
So… where did the information in DNA come from? This is one of the most important and valuable questions in the history of science. Currently, no one knows the answer.
A solution to this problem will become one of the most pivotal scientific and technical discoveries of the 21st century. The winner will receive substantial recognition.
The Challenge Breakthrough
To solve this problem is far more than an object of abstract religious or philosophical discussion. It would demonstrate a mechanism for producing novel, naturally forming information systems, thus opening new channels of scientific discovery.
Such a find would have sweeping implications for Artificial Intelligence research. This would provide a solution to the most perplexing transition currently faced by the Origin Of Life field, namely the origin of coded information.
How could the genetic code (or any coding system) come into being? This would represent a landmark discovery in the history of science and alter our fundamental understanding of the universe.
What You Can Do To Trigger A Breakthrough
Click "Follow" above to be notified of any status updates to the challenge.
Click "Accept Challenge" above to register for the challenge. You will be notified of any status updates and be able to create an entry to the challenge when it opens.
Click on the "Share" button or social media icons above to share this challenge with your friends, your family, or anyone you know who has a passion for discovery.
Leave a comment in our Comments Thread to join the conversation, ask questions or connect with other innovators.
ADDITIONAL RULES
Who can participate
The Challenge is open to all individuals and organizations who are legally allowed to participate, and who comply with all the terms of the Challenge as defined in the Challenge-Specific Agreement.
Selection of Winner
Based on the winning criteria, one prize will be awarded for a total of $100,000. If the discovery is defensibly patentable, the full amount of the prize will be awarded for a total of $10 million. In case of a tie, the winner will be selected at the discretion of the Judging Panel.
Registration and Submissions
All submissions must be received online, via the Challenge website, and all uploads can be in PDF format only. Submission reporting requirements are detailed in Judging.
Challenge Guidelines are subject to change. Registered competitors will receive notification when changes are made, however, we highly encourage you to visit the Challenge Site often to review updates.
**IMPORTANT NOTE** General essays presenting a ‘Theory Of Everything' and metaphysical constructions about the history of life, unfortunately, cannot be considered. Please do not submit materials of this kind. We are looking for entries that offer quantifiable technological progress.
~
Perry Marshall is endorsed in FORBES and INC Magazine and is one of the most expensive business consultants in the world. His Evolution 2.0 Challenge, announced at the Royal Society in London, is the world’s largest science research prize. His book Evolution 2.0 harness a communication engineer’s outsider’s perspective to reveal a century of unrecognized discoveries.
His reinvention of the Pareto Principle is published in Harvard Business Review, and NASA's Jet Propulsion Labs uses his 80/20 Curve as a productivity tool. He wrote the world’s best-selling book on digital advertising, Ultimate Guide to Google AdWords and has consulted in over 300 industries. He has a degree in Electrical Engineering and lives with his family in Chicago.
Guidelines
**IMPORTANT NOTE** General essays presenting a ‘Theory Of Everything' and metaphysical constructions about the history of life, unfortunately, cannot be considered. Please do not submit materials of this kind. We are looking for entries that offer quantifiable technological progress. ALSO, physical experiments that achieve the objectives of this challenge could potentially be dangerous. Our judge, George Church, has cautioned us that such experiments must be carried out under highly controlled conditions. Public safety is of paramount importance to Evolution 2.0.
Maximum length of proposal is 20 pages. (If you have much more data than that then submit a summary and we can review your full data at a later step.)
Challenge and Winning Criteria Defined
1. The Evolution 2.0 Challenge (the “Challenge”) is sponsored by Natural Code LLC, a Nevada limited liability company, also sometimes referred to in these Challenge Guidelines as “Sponsor.” Each entrant to this Challenge who submits a solution to the Challenge is referred to in these Guidelines as an “Innovator.”
2. The Evolution 2.0 Challenge is to discover a purely chemical process that will generate, transmit and receive a simple code--a process by which chemicals self-organize into a code without benefit of designer.
3. To be clear, what the Sponsor is looking for is a process where some chemicals, at some particular concentration of compounds, at the right temperature and pressure, etc. generate, transmit and receive a simple code, without any intelligent being or other life-form creating, transmitting or receiving the code.
4. A successful solution to this Challenge would mean that chemicals alone, without the benefit of minds or brains belonging to humans or the assistance of other living things, have built a simple communication system from scratch. In effect, the jar of chemicals on its own would be assigning meaning to symbols. The configuration of chemicals and not the human inventor would be making creative linguistic choices and creating a coded communication system. Basically, the Sponsor is looking for a formula or transformation process that turns matter into information—directly, with no intelligent being or other life-form making it happen.
5. The coded communication system submitted as a solution to this Challenge must be digital, not analog. So, for example, a system that merely transmits vibrations from one place to another or from one form of energy to another is not acceptable for this Challenge.
6. The system submitted as a solution to this Challenge must have the three integral components of communication, i.e., encoder, code, and decoder, functioning together.
Essential Components of a Communication System (after Claude Shannon, 1948):
All communication systems have an encoder, which produces a message, which is processed by a decoder. DNA transcription and translation matches the pattern in the above diagram. The Sponsor of this Challenge is seeking discovery and proof of a naturally occurring code, which also matches this pattern.
7. The message passed between the encoder and decoder components must be in a sequence of symbols forming characters of a finite alphabet. For this purpose, a “symbol” is a group of k bits considered as a unit. (A more complete definition of “symbol” in the context of this Challenge is set forth on page 340, numbered paragraph 8, of the book, Evolution 2.0). A “character” is a group of n symbols considered as a unit. (For a more complete definition of “character” in the context of this Challenge, see numbered paragraph 9 on page 340 of the book, Evolution 2.0). In the system, n+k must be equal to 5 or more, such that it is a 2-layer system which can represent at least 32 digital states.
8. The submitted solution must contain encoding and decoding tables filled out with their values arising from the submitted system or process.
9. It must be possible to determine objectively whether encoding and decoding have been carried out correctly. For any given system, a procedure should exist for determining whether input correctly corresponds to output. One analogy that demonstrates what the Sponsor means by this is the cause and effect relationship of a keyboard and a computer screen. Pressing an “A” on a computer keyboard should result in the letter “A” appearing on the screen; there is an observable correspondence between the two. The keyboard and screen analogy violates rule #10 below. However, a successful entry will receive a set of (32 or more as in rule #7) digital states on the input end (for example, a defined set of chemical concentrations, temperatures, pressures and light), convert them to an intermediate alphabet (or set of physical-chemical states) in its communication channel, then produce a corresponding set of states in its output. Said entry will not violate rule #10.
10. Human beings may design the experiment that demonstrates the process, employing all manner of state-of-the-art laboratory equipment, creating ideal conditions, etc. However, the actual system submitted for demonstration of the solution to this Challenge may not be preprogrammed with any form of code whatsoever. Any system found to have preprogrammed code in it in any form will be disqualified from the competition.
11. The system submitted for demonstration of the solution to this Challenge may not be directly from any living organism, virus or similar entities. So, for example, phenomena such as bee waggles, dog barks, RNA strands derived from cells, mating calls of birds, etc. are not acceptable elements of a winning solution to this Challenge. RNA that forms spontaneously from simple sets of non-living chemicals (like glycolaldehyde) would be acceptable. Entrant must be prepared to show that their results are not contaminated by previously existing biological material. The submitted material will be examined for containing any pre-existing living entity, or derivatives of previously living entities, with exacting standards. Detection of such materials is an automatic disqualification.
12. The origin of the system submitted for solution to this Challenge must be documented to show that its process of origin can be observed in nature and/or duplicated in a real-world laboratory according to the scientific method.
Partial Solutions to the Problem
Winning of the prize is only assured for the first solver who meets all points of the specification. The specification here outlines the simplest known configuration that constitutes a proper communication system, based on Claude Shannon’s seminal paper “A Mathematical Theory of Communication” (Shannon, 1948). All living organisms rely on this system, which is both a communication system and a Turing machine (Yockey, 2005).
If you have a solution which meets a significant fraction of this specification, the judges and backers of Evolution 2.0 consider such discoveries potentially valuable.
The backers of this prize have extensive business, finance, marketing, distribution, technology and product development expertise, as well as access to capital. Any solution indicating commercial potential is subject to discussion and we are interested in exploring commercial applications of your work. If your solution constitutes significant progress towards the Origin Of Information problem, you should submit your solution. Efforts that do not solve significant portions of the problem will be rejected.
The ultimate winner will need to:
-Provide data showing they have met all portions of the specification -Conduct a live demonstration of the operation of said system -Have their work verified by at least three independent judges appointed by Evolution 2.0
Proposal and Data Requirements
13. The merit of Innovator’s submission will be assessed based first on the content of the write up that Innovator submits. The write-up of the proposed solution should be thorough, specific, clear, and easy to read. The Judges will evaluate the content of the write-ups and will invite various Innovators to demonstrate their solutions under laboratory conditions in the presence of the Judges.
14. The write-up should include descriptions of processes, tools, and techniques utilized in the solution. Be sure to go into sufficient detail, especially in areas there your approach may deviate from conventional or traditional methods.
15. Proposals must be uploaded as a single unlocked PDF document, 20 MB maximum. Embedded hyperlinks to external content, such as videos or animations (maximum two minutes duration recommended) or anything else that might help the Judges come to a decision on a winning idea or concept, are allowed. However, there is no guarantee that the Judges will view that external content, so the proposal document itself must stand on its own.
Prizes to be Awarded
Challenge Milestone
Prize to be Awarded
Sponsor awards initial prize to Winning Innovator (chosen by Judges)
$100,000.00 USD
Winning Innovator who has assigned patent rights in the Technology to Sponsor obtains a Viable Patent on the Technology from the United States Patent and Trademark Office
$10 million USD (as provided in Challenge Guidelines) and an equity interest in Sponsor
16. The first person to submit and successfully demonstrate such a process to the satisfaction of the Challenge Judges will receive from the Sponsor a cash prize of One Hundred Thousand Dollars ($100,000.00) USD. Only one $100,000 Prize will be awarded, and that to the first Innovator in this challenge who successfully demonstrates to the satisfaction of the Judges of this Challenge that Innovator has found a solution to this Challenge that meets all the criteria specified in these Challenge Guidelines. The demonstration of the process must be made at a location in the continental United States of America. All costs associated with this demonstration, except for travel expenses and fees for the Challenge Judges, must be borne by Innovator.
17. If the prize-winning process is also patentable, the “Winning Innovator” (the Innovator who has won the $100,000 Prize) is also eligible to receive the balance of the Prize Fund, provided the Winning Innovator complies with all of the rules and guidelines detailed below and the Innovator’s chemical process proves to be “Viably Patentable” (as that term is defined in these Guidelines). When the patent has been granted, Sponsor’s investors are legally bound to fund a Prize Fund of at least $10 million USD. Sponsor anticipates that it will take a minimum of one year, perhaps longer, to obtain this patent, from the time that the initial $100,000 Prize is awarded. If a Viable Patent is granted on the winning process by the United States Patent and Trademark Office, and the Winning Innovator has complied with all the Guidelines detailed below, the Winning Innovator will receive the balance of the Prize Fund, net of the $100,000 prize money already awarded to the Winning Innovator, the balance to be paid when the patent is granted on the winning process.
18. If Innovator intends to qualify ultimately for the award of the entire Prize Fund and not just the basic $100,000 Prize, Innovator’s initial submission to the Challenge must be made in a confidential manner and meet the disclosure criteria of the United States Patent and Trademark Office. Violation of those criteria voids any agreement made between Innovator and Sponsor.
19. Definition of “Viably Patentable”: The invention is valuable enough and sufficiently protectable by a patent (granted by the United States Patent and Trademark Office) for an investment in the development of this invention to pay for itself before the patent expires. Such a patent granted which appears to be commercially viable in Sponsor’s sole opinion is referred to in these Rules as a “Viable Patent.” If the patent yields $10 million dollars in aggregate, via sales, licensing or contractual deals to any set of people involved in the patent or licensing by the time of the award, then that will be considered unambiguous, and not require an opinion as to whether it meets the definition of a “Viable Patent” in these Rules.
20. The decision of whether the invention is Viably Patentable is in the sole discretion of Sponsor (except as specified in Rule 20). Innovator agrees to make every effort to work with Sponsor and identify a Viably Patentable configuration, if Innovator wins the $100,000 Prize and chooses also to pursue the award of the balance of the Prize Fund.
21. By submitting an entry to this Challenge, every Innovator gives Natural Code LLC the right of first refusal to buy the patent rights to the technology, process and system (the “Technology”) which forms the Innovator’s solution to this Challenge, regardless of Innovator’s pursuit of the balance of the Prize Fund beyond the award of the $100,000 Prize. This right of first refusal provision will be part of the Non-disclosure Agreement that Innovator must sign and will take the form of an option granted to Sponsor by Innovator to purchase the patent rights to the Technology at the same price and terms offered in writing to Innovator by a bona fide purchaser unrelated to Innovator. If Natural Code LLC declines to exercise its right to purchase the patent rights to the Technology, the Innovator is released to pursue other buyers.
22. Natural Code LLC agrees to cover all patent fees if the Winning Innovator agrees to sign over all patent rights in the Invention to Natural Code LLC and a Viable Patent is obtained from the United States Patent and Trademark Office.
23. If the Winning Innovator signs over all patent rights in the Invention to Natural Code LLC and a Viable Patent is granted by the United States Patent and Trademark Office on the process the Winning Innovator submits to solve the Challenge, the Winning Innovator will get the balance of the Prize Fund, net of the $100,000 Prize already paid to the Winning Innovator and will also receive an equity interest in Natural Code LLC or in the business entity created by Natural Code LLC to hold the patent rights on the Technology, as that term is defined in these Guidelines.
24. Both the Winning Innovator and Sponsor will agree in writing to work together, believing in good faith that the discovery of this invention is scientifically, technologically and commercially very valuable. A Non-disparagement clause will be included in the document conveying Winning Innovator’s patent rights to Sponsor.
25. The investing members of Natural Code LLC are legally bound to fund a Prize Fund of at least $10 million USD.
Judges
26. The Innovators’ submissions of solutions to this Challenge will be screened initially as for viability by certain officers or members of Sponsor. As potentially winning solutions are received, Sponsor will engage a minimum of three (3) judges (“Judges”) with appropriate scientific background and credentials to evaluate further the submissions to this Challenge which passed the initial screening. These judges will evaluate those submissions and will determine whether any of these Innovators should be invited to demonstrate their solution in the presence of the Judges under laboratory conditions.
27. The Judges’ decisions, including as to whether any particular solution merits the $100,000 Prize, are final and binding. Sponsor reserves the right in its sole discretion to disqualify at any time any entry that it determines does not comply with the criteria stated on this webpage or with these official Challenge Guidelines generally.
28. Natural Code LLC will post non-qualifying submissions of all entrants who grant permission to do so. Several non-qualifying submissions have been posted and can be viewed at www.evo2.org/submissions.
Communication
29. English is the official language for submissions, proposals, presentations, and all communications.
30. Applicants may be contacted for follow-up information by Sponsor; telephone or Skype interviews may be requested.
Eligibility – Who May Submit Entries
31. The Challenge is open to all individuals or groups of individuals who are over the age of majority in their province, state, territory or country of residence. It excludes employees representatives, relatives, dealers and agents of Natural Code LLC and/or HeroX (and their respective affiliates).
32. You do not need to be an engineer or scientist to enter this Challenge. Anyone from any academic field or discipline may enter the Challenge.
33. Any individual, business entity or other organization may submit their own solutions to the Challenge. However, any solution so submitted must be the original discovery of the Innovator and not a mere reporting of someone else’s discovery.
34. Sponsor reserves the right, at its sole discretion, to disqualify any Innovator who is (i) found to be tampering with the entry process or with the operation and administration of the Challenge; (ii) acting in an unsportsmanlike or disruptive manner, or with the intent to disrupt or undermine the legitimate operation of the Challenge; (iii) or in violation of the Challenge Guidelines at any point.
35. Automated entries or votes sent via bots will be disqualified. Automated and/or repetitive electronic submissions (including but not limited to entries made using any script, macro, bot or contest service) will be automatically disqualified and transmissions from these or related accounts may be blocked. Sponsor reserves the right to seek damages and other remedies from any such Innovator to the fullest extent permitted by law, including but not limited to criminal prosecution.
36. Innovators must comply with these Challenge Guidelines. Innovators will be deemed to have received, understood and agreed to these Challenge Guidelines through their participation in this Challenge, as evidenced by their submitting a solution to the Challenge.
37. No purchase or payment of any kind is necessary to enter or win the competition.
38. Each Innovator must sign a Non-Disclosure Agreement with Sponsor before that Innovator’s initial submission is accepted for review by the Judges.
39. Innovator is responsible for all state, Federal and local income and other taxes, etc. which may be levied against Innovator as a result of winning any of the prizes offered in this Challenge.
40. Innovator is responsible for all expenses related to the initial development of the invention into a demonstrable solution to this Challenge. In other words, all of the costs associated with developing, preparing, demonstrating and submitting a solution to this Challenge will be borne by the Innovator, including Innovator’s transportation and travel expenses if asked by the Judges to demonstrate Innovator’s solution.
Governing Law
41. The Challenge is subject to applicable Federal, state and municipal laws and regulations and is void where prohibited by law. All issues and questions concerning the construction, validity, interpretation and enforceability of these Challenge Guidelines or the rights and obligations as between the Innovator and Sponsor in connection with the Challenge shall be governed by and construed in accordance with the laws of the State of Illinois and the laws of the United States of America as applicable, including procedural provisions, without giving effect to any choice of law or conflict of law rules or provisions that would cause the application of any other jurisdiction’s laws.
42. The decisions of Sponsor and the Judges of this Challenge with respect to all aspects of the Challenge are final and binding.
Licensing and Copyright
43. Any submission made in connection with this Challenge must be an original work created by the Innovator or the Innovator team members, and the Innovators must have all necessary rights in and to the submission.
44. The submission must not infringe upon or violate any laws or any third party rights, including, but not limited to, copyright, patent, trademark, trade secret, privacy, publicity or confidentiality rights or other proprietary or contractual rights and must not include material that is libelous, defamatory, or tortious.
45. Innovators must obtain, and make available to Natural Code LLC upon its request, all necessary permissions, licenses, releases, waivers of moral rights and other approvals from third parties necessary for Natural Code LLC to use and exploit the submission, in whole or in part, including without limitation, to reproduce, make derivatives, edit, modify, translate, distribute, transmit, publish, license and broadcast the submission and the results of Innovator’s demonstration worldwide, by any means.
46. To participate in the Challenge, Innovators must agree to these terms, as amended from time to time during the time period of the Challenge.
47. Applications and submissions will be retained by Sponsor; information and data will be accessed only by Sponsor and its competition partners and not sold or shared.
Disclaimers
48. The specifications posted at http://www.naturalcode.org regarding the competition to provide the winning invention or solution to this Challenge, as well as similar text published in the book Evolution 2.0 (by Perry Marshall), have been expanded and clarified by these Challenge Guidelines. Therefore if there are any contradictions among these sets of published rules and guidelines, the provisions in these Guidelines, as may be later amended, shall govern.
49. These Challenge Guidelines are subject to change. Registered Innovators will receive notification when changes are made. However, Innovators are encouraged to visit the Challenge Site often to review updates.
50. Sponsor is not responsible or liable for late, lost, incomplete, illegible, misdirected, stolen, delayed, damaged or destroyed entries, notifications, or replies; nor for lost, interrupted, inaccessible or unavailable networks, servers, Internet Service Providers, websites or other connection, related to the Challenge; nor for errors of any kind, including but not limited to human, electronic, mechanical and/or technical in nature; nor for failure or technical malfunction of any telephone network or lines, computer and online systems, servers, computer equipment, software, e-mail, players, or browsers on account of technical problems or traffic congestion on the Internet, any websites related to the Challenge, including without limitation the Challenge Webpage, or any combination thereof or otherwise; nor for any injury or damage to Innovator, Innovator’s computer, or any other person’s computer related to or resulting from participating in or downloading material in connection with the Challenge; nor for incorrect or inaccurate information; nor for weather conditions, event cancellations, delay or rescheduling or other factors beyond the Sponsor’s control.
51. CAUTION: ANY ATTEMPT TO UNDERMINE THE LEGITIMATE OPERATION OF THIS CHALLENGE MAY BE A VIOLATION OF CRIMINAL AND CIVIL LAWS AND SHOULD AN ATTEMPT BE MADE, NATURAL CODE LLC RESERVES THE RIGHT TO SEEK DAMAGES OR OTHER REMEDIES FROM ANY SUCH PERSON(S) RESPONSIBLE TO THE FULLEST EXTENT PERMITTED BY LAW.
Interview with Damien Deighan of Data Science Conversations: In this episode we are joined by Perry Marshall to talk about his latest scientific paper entitled “Biology Transcends the Limits of Computation”. We also discuss his $10 million Evolution 2.0 Science Prize, which is the largest prize in the world in science currently.
John Sonmez of Bulldog Mindset Talks with Perry Marshall about…Biology
John Sonmez interviews Perry Marshall and they discuss why it’s impossible for computers in their current form to become conscious; how modern mathematics speaks in a new way to age- old questions about free will; the nature of consciousness; the origin of life and the very nature of reality itself. All this is based on Perry’s paper “Biology transcends the limits of computation.”
Dean Radin discusses his new paper co-authored with Stuart Kauffman
Psychic phenomena have been meticulously documented in hundreds of controlled studies since the 1980s. Mainstream science publications resist acknowledging this but the quality and quantity of evidence is overwhelming.
Dean Radin, who has a bachelor’s degree in electrical engineering and a PhD in Psychology, began discovering this decades ago and founded the Institute for Noetic Sciences.
He recently joined forces with eminent scientist Stuart Kauffman to harmonize the observations with quantum theory.
Construction is Not Computation, and the World is Not a Theorem
Einstein’s theory of relativity overturned Newtonian physics in the early 1900s. Nevertheless “Newtonian” thinking has remained firmly entrenched in science. Certainly all scientists now agree that at the subatomic level and at near light speed, quantum physics overtakes Newtonian physics. But this has had very little effect on biology, and has done nothing to overturn the “reductionist” view of science, which says that everything is merely the sum of its parts and all can be modeled by mathematics.
Stuart Kauffman and computer scientist Andrea Roli have written a new paper that proves evolving biology in principle cannot be reduced to computation. This is as devastating to materialistic science as Gödel’s Incompleteness Theorem was to mathematics. In fact it is equivalent – because it shows that evolving organisms embody incompleteness. Induction not deduction. And induction cannot come from deduction; therefore biology is not strictly computational.
Thus Kauffman and Roli have pulled the rug out from under ultra-traditional views of physics. (Not everyone is going to be happy about this.) Here, Perry Marshall and Stuart Kauffman jazz improvise on the vast implications of this new, holistic view of the universe.
Today if you’re diagnosed with Stage 3 or Stage 4 cancer, your chances of surviving are no better than if you lived in 1930. But your chances are 100 times better when catch it early.
What if you could catch cancer SUPER early – years before any obvious indication of a problem?
And what if you could then solve the problem at its roots so it never recurs at all?
Azra Raza is an oncologist
at Colombia University and author of The First Cell: The Human Costs of Pursuing Cancer to the Last. Here she describes the First Cell Project. This is a collaboration with world class cancer researchers who have discovered how to identify “Giant Cells” that PREDATE and predict the generation of tumors YEARS in advance.
You’ll be privy to the incredibly moving story of Andrew, her daughter’s best friend who died of brain cancer at age 24… and the systemic problems that continue to plague the cancer field and repeat the tragedy of Andrew. Here we discuss why only outsiders will solve these problems.
Be sure and watch my previous interview with Azra Raza at www.evo2.org/azra – it’s a barn burner and provides important background that gives rich context to this new discussion.